|
OpenCV 4.13.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 4.13.0
Open Source Computer Vision
|
前のチュートリアル: 非線形分離可能データに対するサポートベクターマシン
| 原著者 | Theodore Tsesmelis |
| 互換性 | OpenCV >= 3.0 |
このチュートリアルでは、以下の方法を学ぶ:
主成分分析 (PCA) は、データセットの最も重要な特徴を抽出する統計的手法である。
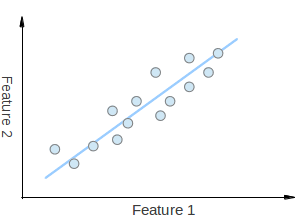
上の図に示すような2次元の点の集合を持っていると考えてほしい。各次元は、関心のある特徴に対応する。ここで、点はランダムな順序で配置されていると主張する人もいるかもしれない。しかしよく見ると、無視しがたい線形パターン(青い線で示される)があることがわかる。PCA の重要な要点は次元削減である。次元削減とは、与えられたデータセットの次元数を減らす処理である。例えば上記の場合、点の集合を1本の線で近似でき、その結果として与えられた点の次元を2次元から1次元へ削減できる。
さらに、点は特徴 1 や特徴 2 の軸方向よりも、青い線に沿った方向に最も大きく分散していることもわかる。これは、青い線に沿った点の位置がわかれば、特徴 1 軸または特徴 2 軸のどこにあるかだけを知っている場合よりも、その点についてより多くの情報を得られることを意味する。
したがって PCA により、データが最も大きく分散する方向を見つけることができる。実際、図中の点の集合に対して PCA を実行した結果は、データセットの主成分である 固有ベクトル (eigenvectors) と呼ばれる2つのベクトルから成る。
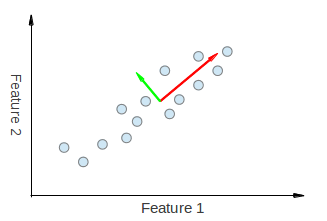
各固有ベクトルの大きさは対応する固有値に符号化されており、その主成分に沿ってデータがどれだけ分散しているかを示す。固有ベクトルの始点は、データセット内の全点の中心である。N 次元のデータセットに PCA を適用すると、N 個の N 次元固有ベクトル、N 個の固有値、および1個の N 次元中心点が得られる。理論はこれで十分なので、これらの考え方をどのようにコードへ落とし込むか見ていこう。
目的は、次元 p の与えられたデータセット X を、より小さい次元 L の別のデータセット Y へ変換することである。言い換えると、行列 X の Karhunen–Loève 変換 (KLT) である行列 Y を求めようとしている。
\[ \mathbf{Y} = \mathbb{K} \mathbb{L} \mathbb{T} \{\mathbf{X}\} \]
データセットを整理する
p 個の変数の観測値の集合から成るデータを持っており、各観測値が L 個の変数のみで記述できるようにデータを削減したいとする(L < p)。さらに、データが n 個のデータベクトル \( x_1...x_n \) の集合として並んでおり、各 \( x_i \) が p 個の変数についての1つのグループ化された観測値を表すとする。
経験平均を計算する
計算した平均値を、次元 \( p\times 1 \) の経験平均ベクトル u に格納する。
\[ \mathbf{u[j]} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{X[i,j]} \]
平均からの偏差を計算する
平均の減算は、データを近似する際の平均二乗誤差を最小化する主成分基底を見つける解法に不可欠な部分である。そこで、次のようにデータを中心化していく。
平均を減算したデータを \( n\times p \) 行列 B に格納する。
\[ \mathbf{B} = \mathbf{X} - \mathbf{h}\mathbf{u^{T}} \]
ここで h はすべて 1 から成る \( n\times 1 \) の列ベクトルである。
\[ h[i] = 1, i = 1, ..., n \]
共分散行列を求める
行列 B 自身との外積から、\( p\times p \) の経験共分散行列 C を求める。
\[ \mathbf{C} = \frac{1}{n-1} \mathbf{B^{*}} \cdot \mathbf{B} \]
ここで * は共役転置演算子である。なお、多くの応用で当てはまるように B が完全に実数から成る場合、「共役転置」は通常の転置と同じになる。
共分散行列の固有ベクトルと固有値を求める
共分散行列 C を対角化する固有ベクトルの行列 V を計算する。
\[ \mathbf{V^{-1}} \mathbf{C} \mathbf{V} = \mathbf{D} \]
ここで D は C の固有値からなる対角行列である。
行列 D は \( p \times p \) の対角行列の形をとる。
\[ D[k,l] = \left\{\begin{matrix} \lambda_k, k = l \\ 0, k \neq l \end{matrix}\right. \]
ここで \( \lambda_j \) は共分散行列 C の j 番目の固有値である
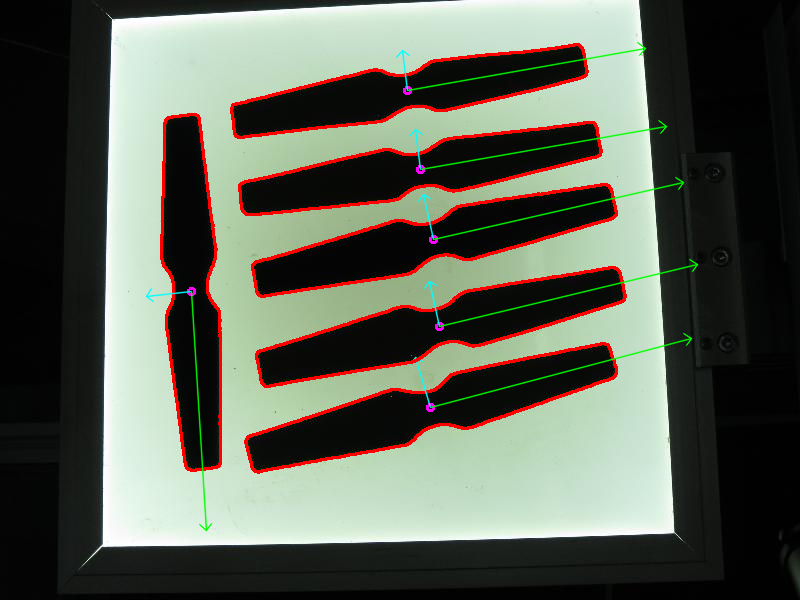
ここでは、対象とする物体を検出できるようにするために必要な前処理を行う。
次に、サイズによって輪郭を検出・フィルタリングし、残った輪郭の向きを求める。
向きは getOrientation() 関数の呼び出しによって抽出され、この関数がPCAの処理全体を行う。
まず、データをサイズ n x 2 の行列に並べる必要がある。ここで n はデータ点の数である。その後、PCA解析を行うことができる。計算された平均(すなわち重心)は cntr 変数に格納され、固有ベクトルと固有値はそれぞれ対応する std::vector に格納される。
最終的な結果は drawAxis() 関数によって可視化される。この関数では主成分が直線で描画され、各固有ベクトルはその固有値で乗算され、平均の位置へ平行移動される。
このコードは画像を開き、検出した対象物体の向きを求め、検出した対象物体の輪郭、中心点、および抽出した向きに対応するx軸とy軸を描画して結果を可視化する。