|
OpenCV 4.13.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 4.13.0
Open Source Computer Vision
|
この章では
赤と青の2種類のデータを持つ下の画像を考える。kNNでは、テストデータに対して、すべての訓練サンプルとの距離を測定し、最小距離のものを採用していた。すべての距離を測定するには多くの時間がかかり、すべての訓練サンプルを保存するには多くのメモリがかかる。しかし画像に示されたデータを考えると、そこまで必要だろうか?
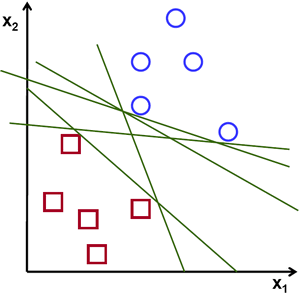
別のアイデアを考える。両方のデータを2つの領域に分ける直線 \(f(x)=ax_1+bx_2+c\) を見つける。新しいテストデータ \(X\) を得たら、それを \(f(x)\) に代入するだけである。\(f(X) > 0\) であれば青のグループに属し、そうでなければ赤のグループに属する。この直線を 決定境界 (Decision Boundary) と呼ぶことができる。これは非常にシンプルでメモリ効率がよい。このように直線(高次元では超平面)で2つに分割できるデータは 線形分離可能 (Linear Separable) と呼ばれる。
そのため上の画像では、このような直線が数多く可能であることが分かる。どれを採用すべきだろうか? 直感的には、その直線はすべての点からできるだけ遠くを通るべきだと言える。なぜか? 入力データにはノイズが含まれている可能性があるからである。このデータが分類精度に影響を与えてはならない。したがって最も遠い直線を採用することで、ノイズに対する耐性がより高まる。そこでSVMが行うのは、訓練サンプルまでの最小距離が最大となる直線(または超平面)を見つけることである。下の画像で中央を通る太線を参照のこと。
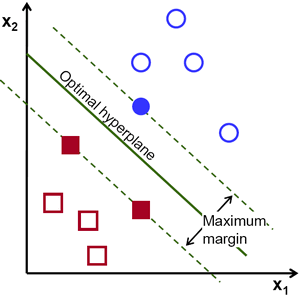
そこで、この決定境界を見つけるには訓練データが必要である。すべて必要だろうか? いや。反対側のグループに近いものだけで十分である。この画像では、それらは1つの青い塗りつぶし円と2つの赤い塗りつぶし四角である。これらを サポートベクター (Support Vectors) と呼び、それらを通る直線を サポート平面 (Support Planes) と呼ぶことができる。それらは決定境界を見つけるのに十分である。すべてのデータについて心配する必要はない。これはデータ削減に役立つ。
何が起こったかというと、まずデータを最もよく表す2つの超平面が見つけられる。例えば、青のデータは \(w^Tx+b_0 > 1\) で表され、赤のデータは \(w^Tx+b_0 < -1\) で表される。ここで \(w\) は 重みベクトル(\(w=[w_1, w_2,..., w_n]\))、\(x\) は特徴ベクトル(\(x = [x_1,x_2,..., x_n]\))である。\(b_0\) は バイアスである。重みベクトルは決定境界の向きを決め、バイアス点はその位置を決める。さて、決定境界はこれらの超平面の中間にあると定義されるので、\(w^Tx+b_0 = 0\) と表される。サポートベクターから決定境界までの最小距離は \(distance_{support \, vectors}=\frac{1}{||w||}\) で与えられる。マージンはこの距離の2倍であり、このマージンを最大化する必要がある。すなわち、いくつかの制約のもとで新しい関数 \(L(w, b_0)\) を最小化する必要があり、それは以下のように表せる:
\[\min_{w, b_0} L(w, b_0) = \frac{1}{2}||w||^2 \; \text{subject to} \; t_i(w^Tx+b_0) \geq 1 \; \forall i\]
ここで \(t_i\) は各クラスのラベルであり、\(t_i \in [-1,1]\) である。
直線で2つに分割できないデータを考える。例えば、'X' が -3 と +3 にあり、'O' が -1 と +1 にある一次元データを考える。明らかにこれは線形分離可能ではない。しかし、この種の問題を解決する方法がある。このデータセットを関数 \(f(x) = x^2\) で写像できれば、'X' は9に、'O' は1になり、これらは線形分離可能である。
あるいは、この一次元データを二次元データに変換することもできる。\(f(x)=(x,x^2)\) 関数を使ってこのデータを写像できる。すると 'X' は (-3,9) と (3,9) になり、'O' は (-1,1) と (1,1) になる。これも線形分離可能である。要するに、低次元空間で線形分離不可能なデータは、高次元空間では線形分離可能になる可能性がより高くなる。
一般に、d次元空間の点をある D次元空間 \((D>d)\) に写像して、線形分離の可能性を確認することができる。低次元の入力(特徴)空間で計算を行うことによって、高次元(カーネル)空間での内積を計算するのに役立つアイデアがある。次の例で説明できる。
二次元空間の2点 \(p=(p_1,p_2)\) と \(q=(q_1,q_2)\) を考える。\(\phi\) を、二次元の点を次のように三次元空間に写像する写像関数とする:
\[\phi (p) = (p_{1}^2,p_{2}^2,\sqrt{2} p_1 p_2) \phi (q) = (q_{1}^2,q_{2}^2,\sqrt{2} q_1 q_2)\]
以下に示すように、2点間で内積を計算するカーネル関数 \(K(p,q)\) を定義する:
\[ \begin{aligned} K(p,q) = \phi(p).\phi(q) &= \phi(p)^T \phi(q) \\ &= (p_{1}^2,p_{2}^2,\sqrt{2} p_1 p_2).(q_{1}^2,q_{2}^2,\sqrt{2} q_1 q_2) \\ &= p_{1}^2 q_{1}^2 + p_{2}^2 q_{2}^2 + 2 p_1 q_1 p_2 q_2 \\ &= (p_1 q_1 + p_2 q_2)^2 \\ \phi(p).\phi(q) &= (p.q)^2 \end{aligned} \]
これは、三次元空間での内積が、二次元空間での内積の二乗を使って実現できることを意味する。これはより高次元の空間にも適用できる。したがって、低次元から高次元の特徴を計算できる。一度それらを写像すれば、高次元空間が得られる。
これらの概念すべてに加えて、誤分類の問題が生じる。そのため、最大マージンを持つ決定境界を見つけるだけでは不十分である。誤分類エラーの問題も考慮する必要がある。場合によっては、マージンは小さいが誤分類が減った決定境界を見つけられることもある。いずれにせよ、最大マージンを持ちつつ誤分類が少ない決定境界を見つけるように、モデルを修正する必要がある。最小化基準は次のように修正される:
\[min \; ||w||^2 + C(distance \; of \; misclassified \; samples \; to \; their \; correct \; regions)\]
下の画像はこの概念を示している。訓練データの各サンプルに対して、新しい引数 \(\xi_i\) が定義される。それは、対応する訓練サンプルから正しい決定領域までの距離である。誤分類されていないものについては、対応するサポート平面上にあるため、その距離はゼロである。
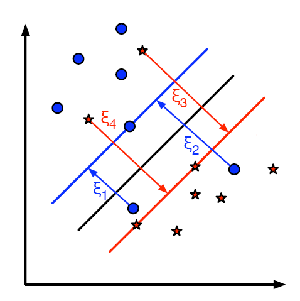
したがって、新しい最適化問題は次のようになる:
\[\min_{w, b_{0}} L(w,b_0) = ||w||^{2} + C \sum_{i} {\xi_{i}} \text{ subject to } y_{i}(w^{T} x_{i} + b_{0}) \geq 1 - \xi_{i} \text{ and } \xi_{i} \geq 0 \text{ } \forall i\]
引数 C はどのように選べばよいのか。この問いの答えが訓練データの分布の仕方に依存することは明らかである。一般的な答えはないが、次の規則を考慮に入れると役立つ: