|
OpenCV 4.13.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 4.13.0
Open Source Computer Vision
|
前のチュートリアル: カスケード分類器
次のチュートリアル: バーコード認識
弱識別器のブースティングされたカスケードを扱う作業には、学習と検出という2つの主要な段階が含まれる。HAARまたはLBPベースのモデルを用いる検出段階については、物体検出のチュートリアル で説明している。本ドキュメントでは、独自の弱識別器ブースティングカスケードを学習するために必要な機能の概要を示す。本ガイドでは、学習データの収集、学習データの準備、実際のモデル学習の実行といった、さまざまな段階を一通り説明する。
本チュートリアルでは、いくつかの公式OpenCVアプリケーションを使用する。opencv_createsamples、opencv_annotation、opencv_traincascade、opencv_visualisation である。
弱識別器のブースティングされたカスケードを学習するには、ポジティブサンプル(検出したい実際の物体を含む)の集合と、ネガティブ画像(検出したくないものすべてを含む)の集合が必要である。ネガティブサンプルの集合は手作業で準備しなければならないのに対し、ポジティブサンプルの集合は opencv_createsamples アプリケーションを使用して作成する。
ネガティブサンプルは、検出したい物体を含まない任意の画像から取得する。サンプルの生成元となるこれらのネガティブ画像は、1行に1つの画像パスを含む特別なネガティブ画像ファイルに列挙する必要がある (絶対パスでも相対パスでも構わない)。なお、ネガティブサンプルとサンプル画像は、背景サンプルまたは背景画像とも呼ばれ、本ドキュメントでは互換的に使用される。
記述された画像はそれぞれ異なるサイズでもよい。ただし、各画像は望ましい学習ウィンドウのサイズ (これはモデルの寸法に対応し、多くの場合は物体の平均サイズである) と同じか、それより大きくする必要がある。なぜなら、これらの画像は、与えられたネガティブ画像をこの学習ウィンドウサイズを持つ複数の画像サンプルへとサブサンプリングするために使用されるからである。
そのようなネガティブ記述ファイルの例:
ディレクトリ構成:
ファイル bg.txt:
ネガティブウィンドウサンプルの集合は、機械学習のステップ(この場合はブースティング)に対して、目的の物体を見つけようとする際に何を探すべきでないかを教えるために使用される。
ポジティブサンプルは opencv_createsamples アプリケーションによって作成される。これらは、目的の物体を見つけようとする際にモデルが実際に何を探すべきかを定義するために、ブースティング処理によって使用される。このアプリケーションは、ポジティブサンプルのデータセットを生成する2つの方法をサポートしている。
最初のアプローチは、非常に剛体的なロゴのような固定された物体に対してはそれなりにうまく機能するが、剛体性の低い物体に対してはかなり早く失敗する傾向がある。その場合は、2番目のアプローチの使用を推奨する。Web上の多くのチュートリアルでは、opencv_createsamples アプリケーションを使って人工的に生成した1000個のポジティブよりも、100枚の実物体画像のほうが優れたモデルにつながる、とすら述べられている。とはいえ最初のアプローチを採用すると決めた場合は、いくつかの点に留意してほしい:
最初のアプローチは、例えば企業ロゴのような単一の物体画像を入力として受け取り、その物体をランダムに回転させ、画像の輝度を変化させ、さらに任意の背景の上に配置することで、与えられた物体画像から大量のポジティブサンプルを作成する。ランダム性の量と範囲は、opencv_createsamples アプリケーションのコマンドライン引数によって制御できる。
コマンドライン引数:
-vec <vec_file_name> : 学習用のポジティブサンプルを含む出力ファイルの名前。-img <image_file_name> : 元となる物体画像(例:企業ロゴ)。-bg <background_file_name> : 背景記述ファイル。ランダムに歪ませた物体のバージョンの背景として使用される画像のリストを含む。-num <number_of_samples> : 生成するポジティブサンプルの数。-bgcolor <background_color> : 背景色(現状ではグレースケール画像が想定されている)。背景色は透明色を表す。圧縮アーティファクトが存在する可能性があるため、色の許容量を -bgthresh で指定できる。bgcolor-bgthresh から bgcolor+bgthresh の範囲内にあるすべてのピクセルは透明として解釈される。-bgthresh <background_color_threshold>-inv : 指定すると、色が反転される。-randinv : 指定すると、色がランダムに反転される。-maxidev <max_intensity_deviation> : 前景サンプルにおけるピクセルの最大輝度偏差。-maxxangle <max_x_rotation_angle> : x軸方向への最大回転角。ラジアンで指定しなければならない。-maxyangle <max_y_rotation_angle> : y軸方向への最大回転角。ラジアンで指定しなければならない。-maxzangle <max_z_rotation_angle> : z軸方向への最大回転角。ラジアンで指定しなければならない。-show : 便利なデバッグオプション。指定すると、各サンプルが表示される。Esc を押すと、各サンプルを表示せずにサンプル作成処理を続行する。-w <sample_width> : 出力サンプルの幅(ピクセル単位)。-h <sample_height> : 出力サンプルの高さ(ピクセル単位)。このようにして opencv_createsamples を実行する場合、サンプルとなる物体インスタンスを作成するために次の手順が用いられる。与えられた元画像が、3つの軸すべての周りでランダムに回転される。選ばれる角度は -maxxangle、-maxyangle、-maxzangle によって制限される。次に、[bg_color-bg_color_threshold; bg_color+bg_color_threshold] の範囲の輝度を持つピクセルが透明として解釈される。前景の輝度には白色ノイズが加えられる。-inv キーが指定されている場合、前景ピクセルの輝度が反転される。-randinv キーが指定されている場合、このサンプルに反転を適用するかどうかをアルゴリズムがランダムに選択する。最後に、得られた画像が背景記述ファイル内の任意の背景の上に配置され、-w と -h で指定された望ましいサイズにリサイズされ、-vec コマンドラインオプションで指定された vec ファイルに格納される。
ポジティブサンプルは、あらかじめマークアップされた画像のコレクションから取得することもでき、これは頑健な物体モデルを構築する際に望ましい方法である。このコレクションは、背景記述ファイルに似たテキストファイルで記述される。このファイルの各行が1枚の画像に対応する。行の最初の要素はファイル名であり、続いて物体アノテーションの数、さらに物体のバウンディング矩形の座標を表す数値(x, y, width, height)が続く。
記述ファイルの例:
ディレクトリ構成:
ファイル info.dat:
画像 img1.jpg は、バウンディング矩形の座標が (140, 100, 45, 45) である単一の物体インスタンスを含む。画像 img2.jpg は2つの物体インスタンスを含む。
このようなコレクションからポジティブサンプルを作成するには、-img の代わりに -info 引数を指定する必要がある:
-info <collection_file_name> : マークアップされた画像コレクションの記述ファイル。この場合、-bg, -bgcolor, -bgthreshold, -inv, -randinv, -maxxangle, -maxyangle, -maxzangle のようなパラメータは単に無視され、もはや使用されない点に注意してほしい。この場合のサンプル作成の仕組みは次のとおりである。物体インスタンスは、元画像から指定されたバウンディングボックスを切り出すことで、与えられた画像から取得される。その後、それらはターゲットとなるサンプルサイズ(-w と -h で定義される)にリサイズされ、-vec パラメータで定義された出力 vec ファイルに格納される。歪みは適用されないため、影響を与える引数は -w、-h、-show、-num のみである。
-info ファイルを作成する手作業は、opencv_annotation ツールを使って行うこともできる。これは、任意の画像内で物体インスタンスの関心領域を視覚的に選択するためのオープンソースツールである。次のサブセクションでは、このアプリケーションの使い方についてより詳しく説明する。
-vec、-w、-h パラメータのみを指定すればよい。opencv/data/vec_files/trainingfaces_24-24.vec。これは次のウィンドウサイズで顔検出器を学習するために使用できる: -w 24 -h 24。OpenCV 3.x 以降、コミュニティは -info ファイルの生成に使用されるオープンソースのアノテーションツールを提供・保守している。OpenCV アプリケーションがビルドされていれば、このツールは opencv_annotation コマンドでアクセスできる。
このツールの使い方は非常に簡単である。ツールはいくつかの必須パラメータといくつかの省略可能なパラメータを受け付ける:
--annotations (必須) : アノテーションを格納したい annotations txt ファイルへのパス。これは続いて -info パラメータに渡される [例 - /data/annotations.txt]--images (必須) : 物体を含む画像が格納されたフォルダへのパス [例 - /data/testimages/]--maxWindowHeight (省略可能) : 入力画像の高さがここで指定した解像度より大きい場合、--resizeFactor を使ってアノテーションしやすいように画像をリサイズする。--resizeFactor (省略可能) : --maxWindowHeight パラメータを使用する際に入力画像をリサイズするのに用いる係数。省略可能なパラメータは一緒にしか使用できない点に注意してほしい。使用できるコマンドの例を以下に示す
このコマンドは、最初の画像とアノテーションに使用するマウスカーソルを含むウィンドウを起動する。アノテーションツールの使い方に関する動画は こちら で見られる。基本的に、アクションを引き起こすいくつかのキー操作がある。左マウスボタンは物体の最初の角を選択するために使用され、その後、満足するまで描画を続け、2回目の左マウスボタンのクリックが登録されると停止する。各選択の後、次の選択肢がある:
c を押す : アノテーションを確定し、アノテーションを緑色にして格納されたことを確認するd を押す : アノテーション一覧から最後のアノテーションを削除する(誤ったアノテーションの除去に便利)n を押す : 次の画像へ進むESC を押す : アノテーションソフトウェアを終了する最終的に、opencv_createsamples の -info 引数に渡せる使用可能なアノテーションファイルが得られる。
次のステップは、事前に用意したポジティブおよびネガティブデータセットに基づき、弱識別器のブースト済みカスケードを実際に学習することである。
opencv_traincascade アプリケーションのコマンドライン引数を目的別にグループ化したもの:
-data <cascade_dir_name> : 学習済み識別器を格納する場所。このフォルダは事前に手動で作成しておく必要がある。-vec <vec_file_name> : ポジティブサンプルを含む vec ファイル(opencv_createsamples ユーティリティで作成)。-bg <background_file_name> : 背景記述ファイル。これはネガティブサンプル画像を含むファイルである。-numPos <number_of_positive_samples> : 各識別器ステージの学習で使用するポジティブサンプルの数。-numNeg <number_of_negative_samples> : 各識別器ステージの学習で使用するネガティブサンプルの数。-numStages <number_of_stages> : 学習するカスケードステージの数。-precalcValBufSize <precalculated_vals_buffer_size_in_Mb> : 事前計算した特徴量の値を格納するバッファのサイズ(Mb 単位)。割り当てるメモリが多いほど学習処理は高速になるが、-precalcValBufSize と -precalcIdxBufSize の合計が利用可能なシステムメモリを超えないように注意すること。-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb> : 事前計算した特徴量のインデックスを格納するバッファのサイズ(Mb 単位)。割り当てるメモリが多いほど学習処理は高速になるが、-precalcValBufSize と -precalcIdxBufSize の合計が利用可能なシステムメモリを超えないように注意すること。-baseFormatSave : この引数は Haar-like 特徴の場合に有効である。指定すると、カスケードは旧形式で保存される。これは後方互換性のためだけに用意されており、非推奨の旧インターフェースから移行できないユーザーが、少なくとも新しいインターフェースを使ってモデルを学習できるようにするためのものである。-numThreads <max_number_of_threads> : 学習中に使用するスレッドの最大数。実際に使用されるスレッド数は、マシンやコンパイルオプションによってこれより少なくなる場合があることに注意。デフォルトでは、この最適化に必要な TBB サポートを有効にして OpenCV をビルドした場合、利用可能な最大スレッド数が選択される。-acceptanceRatioBreakValue <break_value> : この引数は、モデルをどの程度の精度で学習し続けるべきか、いつ停止すべきかを決定するために使用する。モデルが学習データに過学習しないようにするため、10e-5 を超えて学習しないことが良いガイドラインである。デフォルトではこの値は -1 に設定されており、この機能は無効になっている。-stageType <BOOST(default)> : ステージの種類。現時点ではステージの種類としてブースト済み識別器のみがサポートされている。-featureType<{HAAR(default), LBP}> : 特徴の種類: HAAR - Haar-like 特徴、LBP - 局所バイナリパターン。-w <sampleWidth> : 学習サンプルの幅(ピクセル単位)。学習サンプル作成時(opencv_createsamples ユーティリティ)に使用した値と完全に同じでなければならない。-h <sampleHeight> : 学習サンプルの高さ(ピクセル単位)。学習サンプル作成時(opencv_createsamples ユーティリティ)に使用した値と完全に同じでなければならない。-bt <{DAB, RAB, LB, GAB(default)}> : ブースト済み識別器の種類: DAB - Discrete AdaBoost、RAB - Real AdaBoost、LB - LogitBoost、GAB - Gentle AdaBoost。-minHitRate <min_hit_rate> : 識別器の各ステージで望ましい最小ヒット率。全体のヒット率は (min_hit_rate ^ number_of_stages) として推定できる。[292] §4.1。-maxFalseAlarmRate <max_false_alarm_rate> : 識別器の各ステージで望ましい最大誤警報率。全体の誤警報率は (max_false_alarm_rate ^ number_of_stages) として推定できる。[292] §4.1。-weightTrimRate <weight_trim_rate> : トリミングを使用するかどうか、およびその重みを指定する。妥当な選択は 0.95 である。-maxDepth <max_depth_of_weak_tree> : 弱学習木の最大深さ。妥当な選択は 1 で、これはスタンプ(stump)の場合である。-maxWeakCount <max_weak_tree_count> : 各カスケードステージにおける弱学習木の最大数。ブースト済み識別器(ステージ)は、指定した -maxFalseAlarmRate を達成するために必要な数(<=maxWeakCount)の弱学習木を持つ。-mode <BASIC (default) | CORE | ALL> : 学習で使用する Haar 特徴セットの種類を選択する。BASIC は直立特徴のみを使用し、ALL は直立特徴と 45 度回転特徴を合わせた完全なセットを使用する。詳細は [173] を参照。opencv_traincascade アプリケーションの処理が完了すると、学習済みカスケードは -data フォルダ内の cascade.xml ファイルに保存される。このフォルダ内のその他のファイルは学習が中断された場合のために作成されるものなので、学習完了後に削除してよい。
学習が完了したので、カスケード識別器をテストできる!
学習済みカスケードを可視化して、どの特徴を選択したか、各ステージがどの程度複雑かを確認することは、時として有用である。このために OpenCV は opencv_visualisation アプリケーションを提供している。このアプリケーションには次のコマンドがある:
--image (必須) : オブジェクトモデルの参照画像へのパス。これは opencv_createsamples と opencv_traincascade の両アプリケーションに渡した寸法 [-w,-h] を持つアノテーションでなければならない。--model (必須) : 学習済みモデルへのパス。これは opencv_traincascade アプリケーションの -data 引数に指定したフォルダ内にあるはずである。--data (省略可能) : データフォルダ(事前に手動で作成しておく必要がある)を指定すると、ステージの出力と特徴のビデオが格納される。コマンドの例を以下に示す
現在の可視化ツールのいくつかの制限
--image 引数に渡す、元のモデル寸法を持つサンプルウィンドウである必要がある。カスケード識別器ファイルと同じ前処理(24x24 ピクセル画像、グレースケール変換、ヒストグラム平坦化)を施した Angelina Jolie の所定のウィンドウに対して、HAAR/LBP の顔モデルを実行した例:
各ステージの各特徴を可視化したビデオが作成される:

各ステージは、将来の特徴の検証のために画像として保存される:
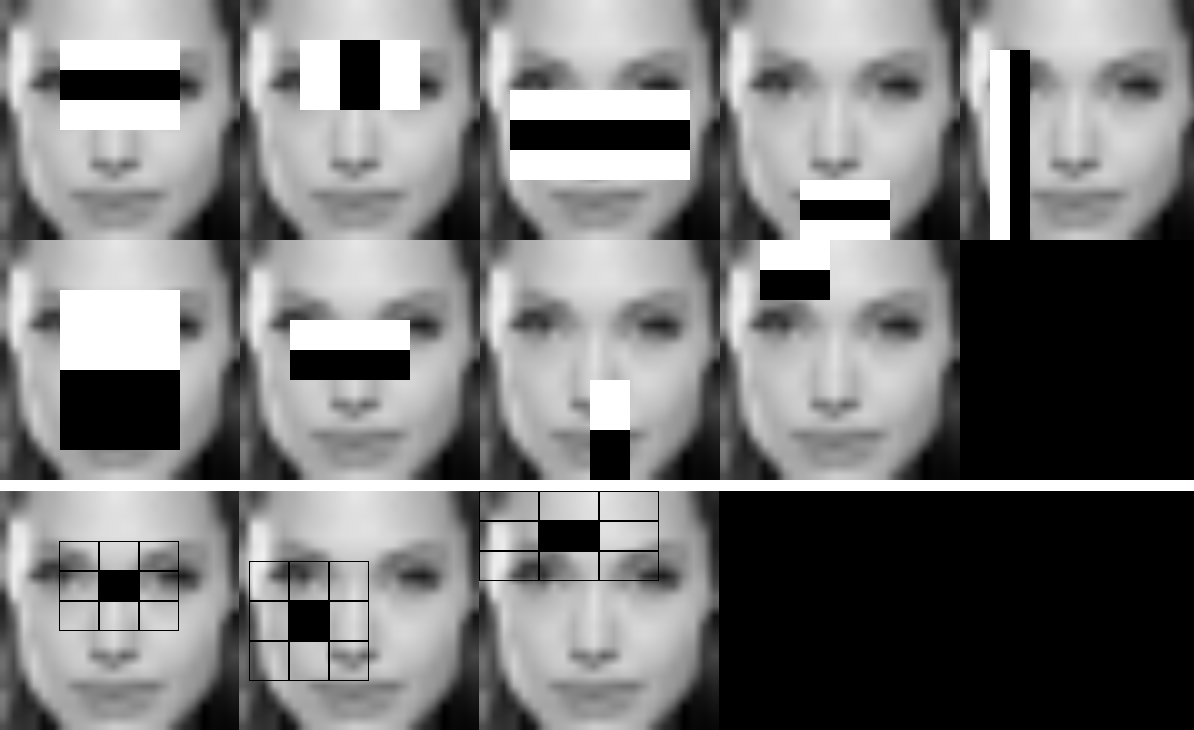
この成果物は StevenPuttemans による OpenCV 3 Blueprints のために作成されたが、Packt Publishing が OpenCV への統合に同意した。