|
OpenCV 4.13.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 4.13.0
Open Source Computer Vision
|
機械学習アルゴリズムには学習データという概念がある。学習データは複数の要素から構成される。
このように、学習データはかなり複雑な構造を持つことがある。さらに、非常に大きい場合や、すべてが一度には利用できない場合もあるため、この概念を抽象化する必要がある。OpenCV ml にはそのために cv::ml::TrainData クラスがある。
この単純な分類モデルは、各クラスの特徴ベクトルが正規分布に従う(ただし、必ずしも独立に分布するとは限らない)と仮定する。したがって、データ分布全体の関数はガウス混合分布であり、クラスごとに1つの成分を持つと仮定される。アルゴリズムは学習データを用いて各クラスの平均ベクトルと共分散行列を推定し、それらを予測に用いる。
このアルゴリズムはすべての学習サンプルをキャッシュし、新しいサンプルに対しては、そのサンプルの最近傍の一定数(K)を解析して、投票や重み付き和の計算などにより応答を予測する。この手法は、予測時に与えられたベクトルに最も近い既知応答の特徴ベクトルを探すことから、「事例による学習(learning by example)」と呼ばれることもある。
サポートベクターマシン(SVM)は元々、最適な2値(2クラス)分類器を構築する手法であった。後にこの手法は回帰やクラスタリングの問題へと拡張された。SVMはカーネルベース手法の一種である。カーネル関数を用いて特徴ベクトルをより高次元の空間へ写像し、その空間内で最適な線形識別関数、すなわち学習データに最も適合する最適な超平面を構築する。SVMの場合、カーネルは明示的に定義されない。代わりに、超空間内の任意の2点間の距離を定義する必要がある。
この解は最適であり、これは分離超平面と両クラス(2クラス分類器の場合)からの最も近い特徴ベクトルとの間のマージンが最大になることを意味する。超平面に最も近い特徴ベクトルはサポートベクターと呼ばれ、これは他のベクトルの位置が超平面(決定関数)に影響しないことを意味する。
OpenCVのSVM実装は [52] に基づいている。
StatModel::predict(samples, results, flags) を使用する。flags=StatModel::RAW_OUTPUT を渡すと、SVMから生の応答(回帰、1クラスまたは2クラス分類問題の場合)を取得できる。
本節で取り上げるMLクラスは、[42] で説明されている分類回帰木(Classification and Regression Tree)アルゴリズムを実装している。
cv::ml::DTrees クラスは、単一の決定木または決定木の集合を表す。これは RTrees と Boost の基底クラスでもある。
決定木は二分木(各非葉ノードが2つの子ノードを持つ木)である。分類にも回帰にも使用できる。分類の場合、各木の葉にはクラスラベルが付与され、複数の葉が同じラベルを持つこともある。回帰の場合は、各木の葉にも定数が割り当てられるため、近似関数は区分定数関数となる。
葉ノードに到達し、入力特徴ベクトルに対する応答を得るため、予測手順は根ノードから始まる。各非葉ノードでは、そのノードに格納されたインデックスを持つ特定の変数の値に基づいて、手順は左(次に観測するノードとして左の子ノードを選択)または右へ進む。次のような変数があり得る。
このように、各ノードでは(variable_index , decision_rule (threshold/subset) )という対が使われる。この対は分割(split)(変数 variable_index による分割)と呼ばれる。葉ノードに到達すると、そのノードに割り当てられた値が予測手順の出力として使われる。
入力ベクトルの特定の特徴が欠落していることがある(たとえば暗闇では物体の色を判定するのが難しい)。この場合、予測手順は特定のノードで行き詰まることがある(前述の例では、ノードが色で分割されている場合)。こうした状況を避けるため、決定木は代理分割(surrogate splits)と呼ばれるものを用いる。すなわち、最良の「主分割(primary split)」に加えて、各木のノードは、ほぼ同じ結果をもたらす1つ以上の別の変数によっても分割され得る。
木は根ノードから始めて再帰的に構築される。すべての学習データ(特徴ベクトルと応答)が根ノードの分割に使われる。各ノードでは、ある基準に基づいて最適な決定規則(最良の「主分割」)が求められる。機械学習では、分類にはジニ「純度」基準が、回帰には誤差の二乗和が使われる。次に、必要であれば代理分割が求められる。代理分割は、学習データ上での主分割の結果に類似している。すべてのデータは、(予測手順と同様に)主分割と代理分割を用いて左右の子ノードに分けられる。その後、手順は左右両方のノードを再帰的に分割する。各ノードにおいて、再帰手順は次のいずれかの場合に停止する(すなわち、それ以上ノードを分割しない)ことがある。
木の構築後、必要であれば交差検証の手順を用いて枝刈り(プルーニング)を行ってもよい。すなわち、モデルの過学習につながり得る木の一部の枝を切り落とす。通常、この手順は単独の決定木にのみ適用される。一般に、木のアンサンブルは十分に小さい木を構築し、過学習に対して独自の保護機構を用いる。
決定木の明白な用途である予測に加えて、木はさまざまなデータ分析にも使える。構築された決定木アルゴリズムの重要な性質の1つは、各変数の重要度(相対的な決定力)を計算できることである。たとえば、メッセージ中に出現する単語の集合を特徴ベクトルとして使うスパムフィルタでは、変数の重要度評価を用いて最も「スパムを示唆する」単語を特定でき、辞書のサイズを妥当に保つのに役立つ。
各変数の重要度は、木の中でその変数に対するすべての分割(主分割と代理分割)にわたって計算される。したがって、変数の重要度を正しく計算するには、欠測データがなくても学習パラメータで代理分割を有効にしておく必要がある。
一般的な機械学習のタスクは教師あり学習である。教師あり学習では、入力 \(x\) と出力 \(y\) の間の関数関係 \(F: y = F(x)\) を学習することが目標となる。質的な出力を予測することは分類と呼ばれ、量的な出力を予測することは回帰と呼ばれる。
ブースティングは、教師あり分類学習タスクに対する解を提供する強力な学習概念である。多くの「弱い」分類器の性能を組み合わせて、強力な委員会を構成する [279]。弱い分類器に求められるのは偶然より良いことだけであり、したがって非常に単純で計算コストも低くてよい。しかし、それらの多くを巧妙に組み合わせると、SVMやニューラルネットワークなどのほとんどの「一枚岩の」強い分類器をしばしば上回る、強力な分類器が得られる。
決定木は、ブースティング方式で使われる最も一般的な弱い分類器である。多くの場合、木あたり1つの分割ノードしか持たない最も単純な決定木(切り株、stumpsと呼ばれる)で十分である。
ブーストされたモデルは、\(x_i \in{R^K}\) かつ \(y_i \in{-1, +1}\) である \(N\) 個の学習例 \({(x_i,y_i)}1N\) に基づく。\(x_i\) は \(K\) 成分のベクトルである。各成分は、対象の学習タスクに関連する特徴を符号化する。所望の2クラス出力は -1 と +1 として符号化される。
ブースティングのさまざまな変種は、Discrete Adaboost、Real AdaBoost、LogitBoost、Gentle AdaBoost として知られている [99]。これらはすべて全体構造が非常に似ている。したがって、本章では以下に概説する標準的な2クラスの Discrete AdaBoost アルゴリズムのみに焦点を当てる。最初に各サンプルに同じ重みが割り当てられる(ステップ2)。次に、重み付き学習データ上で弱い分類器 \(f_{m(x)}\) が学習される(ステップ3a)。その重み付き学習誤差とスケーリング係数 \(c_m\) が計算される(ステップ3b)。誤分類された学習サンプルの重みが増やされる(ステップ3c)。その後すべての重みが正規化され、次の弱い分類器を見つける処理がさらに \(M\) -1 回続けられる。最終的な分類器 \(F(x)\) は、個々の弱い分類器にわたる重み付き和の符号である(ステップ4)。
2クラス Discrete AdaBoost アルゴリズム
ブーストされたモデルの計算時間を、精度を大幅に損なうことなく削減するため、影響トリミング(influence trimming)技法を利用できる。学習アルゴリズムが進行しアンサンブル内の木の数が増えるにつれて、より多くの学習サンプルが正しく、かつより高い確信度で分類されるようになり、その結果これらのサンプルは後続の反復でより小さい重みを受け取る。相対的な重みが非常に小さい例は、弱い分類器の学習にほとんど影響しない。したがって、そのような例は、得られる分類器にあまり影響を与えることなく、弱い分類器の学習中に除外できる。この処理は weight_trim_rate パラメータで制御される。重み総量のうち合計割合が weight_trim_rate となる例のみが弱い分類器の学習に使われる。なお、すべての学習例の重みは各学習反復で再計算される。特定の反復で削除された例が、後段の一部の弱い分類器の学習に再び使われることもある [99]
StatModel::predict(samples, results, flags) を使用する。flags=StatModel::RAW_OUTPUT を渡すと、Boost分類器から生の和を取得できる。
ランダムツリーは Leo Breiman と Adele Cutler によって導入された: http://www.stat.berkeley.edu/users/breiman/RandomForests/。このアルゴリズムは分類問題と回帰問題の両方を扱える。ランダムツリーは木予測器の集合(アンサンブル)であり、本節では以降これをフォレスト(forest)と呼ぶ(この用語も L. Breiman によって導入された)。分類は次のように行われる。ランダムツリー分類器は入力特徴ベクトルを受け取り、フォレスト内のすべての木でそれを分類し、最多の「票」を得たクラスラベルを出力する。回帰の場合、分類器の応答はフォレスト内のすべての木の応答の平均である。
すべての木は同じパラメータで、ただし異なる学習集合上で学習される。これらの集合は、ブートストラップ手順を用いて元の学習集合から生成される。すなわち、各学習集合について、元の集合と同じ数のベクトル( =N )をランダムに選択する。ベクトルは復元抽出で選ばれる。つまり、あるベクトルは複数回出現し、あるベクトルは含まれないこともある。学習された各木の各ノードでは、最良の分割を見つけるためにすべての変数が使われるのではなく、それらのランダムな部分集合が使われる。各ノードで新しい部分集合が生成される。ただし、そのサイズはすべてのノードおよびすべての木で固定である。これは学習パラメータであり、デフォルトでは \(\sqrt{number\_of\_variables}\) に設定される。構築された木はいずれも枝刈りされない。
ランダムツリーでは、交差検証やブートストラップといった精度推定の手順、あるいは学習誤差の推定を得るための別個のテスト集合は必要ない。誤差は学習中に内部的に推定される。現在の木の学習集合を復元抽出によって取り出すと、一部のベクトルは除外される(いわゆるoob(out-of-bag、バッグ外)データ)。oobデータのサイズはおよそ N/3 である。分類誤差は、このoobデータを用いて次のように推定される。
ランダムツリーの使用例については、OpenCVディストリビューションのletter_recog.cppサンプルを参照のこと。
参考文献:
期待値最大化法 (Expectation Maximization, EM) アルゴリズムは、指定した混合数のガウス混合分布の形で表される多変量確率密度関数の引数を推定する。
d次元ユークリッド空間からガウス混合分布に従って抽出された、N個の特徴ベクトルの集合 { \(x_1, x_2,...,x_{N}\) } を考える:
\[p(x;a_k,S_k, \pi _k) = \sum _{k=1}^{m} \pi _kp_k(x), \quad \pi _k \geq 0, \quad \sum _{k=1}^{m} \pi _k=1,\]
\[p_k(x)= \varphi (x;a_k,S_k)= \frac{1}{(2\pi)^{d/2}\mid{S_k}\mid^{1/2}} exp \left \{ - \frac{1}{2} (x-a_k)^TS_k^{-1}(x-a_k) \right \} ,\]
ここで \(m\) は混合数、\(p_k\) は平均 \(a_k\) と共分散行列 \(S_k\) を持つ正規分布の密度、\(\pi_k\) はk番目の混合の重みである。混合数 \(M\) とサンプル \(x_i\), \(i=1..N\) が与えられると、アルゴリズムはすべての混合引数、すなわち \(a_k\), \(S_k\), \(\pi_k\) の最尤推定値 (MLE) を求める:
\[L(x, \theta )=logp(x, \theta )= \sum _{i=1}^{N}log \left ( \sum _{k=1}^{m} \pi _kp_k(x) \right ) \to \max _{ \theta \in \Theta },\]
\[\Theta = \left \{ (a_k,S_k, \pi _k): a_k \in \mathbbm{R} ^d,S_k=S_k^T>0,S_k \in \mathbbm{R} ^{d \times d}, \pi _k \geq 0, \sum _{k=1}^{m} \pi _k=1 \right \} .\]
EMアルゴリズムは反復的な手続きである。各反復は2つのステップから成る。第1ステップ(期待値ステップ、すなわちEステップ)では、現在利用可能な混合引数の推定値を使って、サンプルiが混合kに属する確率 \(p_{i,k}\)(以下の式では \(\alpha_{i,k}\) と表記)を求める:
\[\alpha _{ki} = \frac{\pi_k\varphi(x;a_k,S_k)}{\sum\limits_{j=1}^{m}\pi_j\varphi(x;a_j,S_j)} .\]
第2ステップ(最大化ステップ、すなわちMステップ)では、計算した確率を使って混合引数の推定値を精緻化する:
\[\pi _k= \frac{1}{N} \sum _{i=1}^{N} \alpha _{ki}, \quad a_k= \frac{\sum\limits_{i=1}^{N}\alpha_{ki}x_i}{\sum\limits_{i=1}^{N}\alpha_{ki}} , \quad S_k= \frac{\sum\limits_{i=1}^{N}\alpha_{ki}(x_i-a_k)(x_i-a_k)^T}{\sum\limits_{i=1}^{N}\alpha_{ki}}\]
あるいは、\(p_{i,k}\) の初期値が与えられる場合は、アルゴリズムをMステップから開始してもよい。\(p_{i,k}\) が未知のもう1つの代替策は、より単純なクラスタリングアルゴリズムを使って入力サンプルを事前クラスタリングし、初期の \(p_{i,k}\) を得ることである。多くの場合(機械学習を含む)、この目的にはk-meansアルゴリズムが使われる。
EMアルゴリズムの主な問題の1つは、推定すべき引数の数が多いことである。引数の大部分は共分散行列にあり、それぞれが \(d \times d\) 個の要素を持つ(\(d\) は特徴空間の次元数)。しかし、多くの実用的な問題では、共分散行列は対角行列、あるいは \(\mu_k*I\) にすら近い(ここで \(I\) は単位行列、\(\mu_k\) は混合に依存する「スケール」引数である)。そのため、頑健な計算手法では、共分散行列に対してより厳しい制約を課して開始し、得られた推定引数を制約の少ない最適化問題の入力として使うことができる(多くの場合、対角共分散行列ですでに十分に良い近似となる)。
参考文献:
MLは順伝播型人工ニューラルネットワーク、より具体的には、最も一般的に使われるタイプのニューラルネットワークである多層パーセプトロン (MLP) を実装している。MLPは入力層、出力層、および1つ以上の隠れ層から成る。MLPの各層には、前後の層のニューロンと方向性をもって接続された1つ以上のニューロンが含まれる。以下の例は、3つの入力、2つの出力、および5つのニューロンを含む隠れ層を持つ3層パーセプトロンを表す:
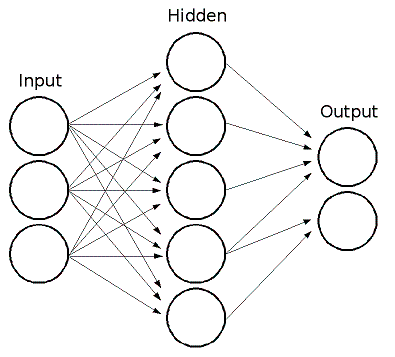
MLP内のすべてのニューロンは同様である。各ニューロンは複数の入力リンク(前の層の複数のニューロンの出力値を入力として受け取る)と複数の出力リンク(次の層の複数のニューロンに応答を渡す)を持つ。前の層から取得した値は、ニューロンごとに固有の重みとバイアス項を加えて合計される。この合計は活性化関数 \(f\) を使って変換されるが、この関数もニューロンごとに異なる場合がある。
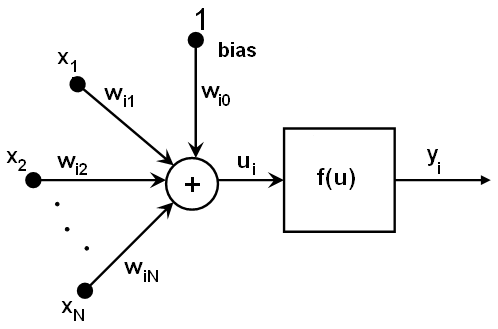
言い換えると、層 \(n\) の出力 \(x_j\) が与えられると、層 \(n+1\) の出力 \(y_i\) は次のように計算される:
\[u_i = \sum _j (w^{n+1}_{i,j}*x_j) + w^{n+1}_{i,bias}\]
\[y_i = f(u_i)\]
さまざまな活性化関数を使うことができる。MLは3つの標準的な関数を実装している:
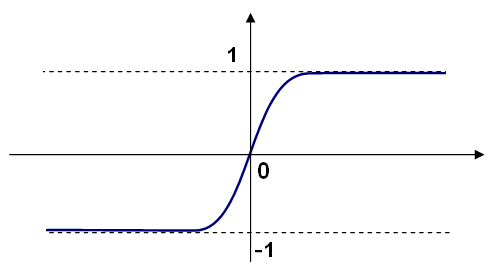
MLでは、すべてのニューロンが同じ活性化関数を持ち、同じ自由引数 ( \(\alpha, \beta\) ) を持つ。これらはユーザが指定し、学習アルゴリズムによって変更されることはない。
したがって、学習済みネットワーク全体は次のように動作する:
したがって、ネットワークを計算するには、すべての重み \(w^{n+1)}_{i,j}\) を知る必要がある。重みは学習アルゴリズムによって計算される。アルゴリズムは、対応する出力ベクトルを伴う複数の入力ベクトルから成る学習セットを受け取り、ネットワークが与えられた入力ベクトルに対して望ましい応答を返せるように、重みを反復的に調整する。
ネットワークのサイズ(隠れ層の数とそのサイズ)が大きいほど、ネットワークの潜在的な柔軟性は高まる。学習セットでの誤差は任意に小さくできる。しかし同時に、学習済みネットワークは学習セットに含まれるノイズも「学習」してしまうため、ネットワークサイズがある限界に達すると、通常テストセットでの誤差は増加し始める。さらに、大きなネットワークは小さなネットワークよりはるかに長い学習時間を要するため、cv::PCA などの手法を使ってデータを前処理し、本質的な特徴のみで小さなネットワークを学習させるのが妥当である。
MLPのもう1つの特徴は、カテゴリデータをそのままでは扱えないことである。ただし、回避策がある。入力層または出力層(\(n>2\) のn クラス分類器の場合)のある特徴がカテゴリ変数であり、\(M>2\) 個の異なる値を取りうる場合、それをM個の要素から成る2値タプルとして表現するのが理にかなっている。このタプルでは、特徴がM個の可能な値のうちi 番目の値に等しい場合に限り、i 番目の要素が1となる。これにより入力層/出力層のサイズは増えるが、学習アルゴリズムの収束は速まり、同時にこうした変数の「ファジー」な値、すなわち固定値の代わりに確率のタプルを扱えるようになる。
MLはMLPの学習に2つのアルゴリズムを実装している。1つ目のアルゴリズムは古典的なランダム逐次バックプロパゲーションアルゴリズムである。2つ目(デフォルト)はバッチRPROPアルゴリズムである。
MLは確率的な分類手法であるロジスティック回帰を実装している。ロジスティック回帰は2値分類アルゴリズムであり、サポートベクターマシン (SVM) と密接に関連している。SVMと同様に、ロジスティック回帰は数字認識(与えられた画像から0, 1, 2, 3,... のような数字を認識する)のような多クラス分類問題にも拡張できる。このバージョンのロジスティック回帰は2値分類と多クラス分類の両方をサポートする(多クラスの場合は複数の2クラス分類器を作成する)。ロジスティック回帰分類器を学習させるには、バッチ勾配降下法 (Batch Gradient Descent) およびミニバッチ勾配降下法 (Mini-Batch Gradient Descent) アルゴリズムが使われる(http://en.wikipedia.org/wiki/Gradient_descent_optimization を参照)。ロジスティック回帰は識別的分類器である(詳細は http://www.cs.cmu.edu/~tom/NewChapters.html を参照)。ロジスティック回帰はLogisticRegressionとしてC++クラスで実装されている。
ロジスティック回帰では、仮説 \(0 \leq h_\theta(x) \leq 1\) が達成されるように、学習引数 \(\theta\) を最適化しようとする。\(h_\theta(x) = g(h_\theta(x))\) であり、ロジスティック関数(シグモイド関数)として \(g(z) = \frac{1}{1+e^{-z}}\) を用いる。ロジスティック回帰における「ロジスティック」という用語はこの関数を指す。クラス0とクラス1の2値分類問題のデータが与えられたとき、\(h_\theta(x) \geq 0.5\) であればそのデータインスタンスはクラス1に属し、\(h_\theta(x) < 0.5\) であればクラス0に属すると判定できる。
ロジスティック回帰では、学習誤差を減らし、高い学習精度を確保するために、適切な引数を選ぶことが極めて重要である:
ロジスティック回帰分類器の学習引数のサンプルセットは、次のように初期化できる: