|
OpenCV 4.13.0
Open Source Computer Vision
|
|
OpenCV 4.13.0
Open Source Computer Vision
|
以下で説明する物体検出器は、Paul Viola [291] によって最初に提案され、Rainer Lienhart [173] によって改良された。
まず、分類器(具体的にはhaar-like特徴を扱うブースト分類器のカスケード)を、特定の物体(例えば顔や車)の数百枚のサンプル画像で学習させる。これらは同じサイズ(例えば20x20)にスケーリングされたもので、ポジティブサンプルと呼ばれる。また、同じサイズの任意の画像であるネガティブサンプルも用いる。
分類器が学習されると、入力画像内の関心領域(学習時と同じサイズ)に適用できる。分類器は、その領域に物体(例えば顔や車)が写っている可能性が高い場合に「1」を、そうでない場合に「0」を出力する。画像全体から物体を探すには、探索ウィンドウを画像全体で移動させ、分類器を使って各位置をチェックすればよい。分類器は容易に「リサイズ」できるように設計されており、これによって関心のある物体をさまざまなサイズで見つけることができる。これは画像そのものをリサイズするよりも効率的である。したがって、画像内のサイズが未知の物体を見つけるには、スキャン処理を異なるスケールで複数回行う必要がある。
分類器の名前に含まれる「カスケード」という語は、得られる分類器が、関心領域に対して順次適用される複数のより単純な分類器(ステージ)で構成されることを意味する。あるステージで候補が棄却されるか、すべてのステージを通過するまで適用が続く。「ブースト」という語は、カスケードの各ステージの分類器がそれ自体複雑であり、4種類のブースティング手法(重み付き投票)のいずれかを用いて基本分類器から構築されることを意味する。現在、Discrete Adaboost、Real Adaboost、Gentle Adaboost、Logitboost がサポートされている。基本分類器は、少なくとも2つの葉を持つ決定木分類器である。haar-like特徴が基本分類器への入力となり、以下に説明するように計算される。現在のアルゴリズムは以下のhaar-like特徴を使用する。
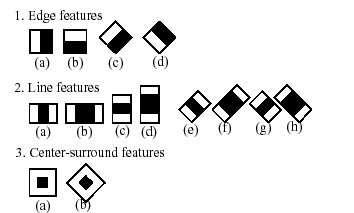
特定の分類器で使われる特徴は、その形状(1a、2bなど)、関心領域内での位置、およびスケール(このスケールは検出ステージで用いるスケールとは異なるが、これら2つのスケールは乗算される)によって指定される。例えば、3番目のライン特徴(2c)の場合、応答は、特徴全体(2本の白い縞と中央の黒い縞を含む)を覆う矩形下の画像ピクセルの総和と、面積の大きさの違いを補正するために3倍した黒い縞下の画像ピクセルの総和との差として計算される。矩形領域にわたるピクセル値の総和は、積分画像を使って高速に計算される(以下および integral の説明を参照)。
詳細については対応するチュートリアルを確認すること。
以下のリファレンスは検出部分のみに関するものである。サンプルの集合からブースト分類器のカスケードを学習できる opencv_traincascade という別のアプリケーションがある。
クラス | |
| class | cv::BaseCascadeClassifier |
| class | cv::CascadeClassifier |
| 物体検出のためのカスケード分類器クラス。 続きを読む... | |
| struct | cv::DefaultDeleter< CvHaarClassifierCascade > |
| class | cv::DetectionBasedTracker |
列挙型 | |
| enum | { cv::CASCADE_DO_CANNY_PRUNING = 1 , cv::CASCADE_SCALE_IMAGE = 2 , cv::CASCADE_FIND_BIGGEST_OBJECT = 4 , cv::CASCADE_DO_ROUGH_SEARCH = 8 } |
関数 | |
| Ptr< BaseCascadeClassifier::MaskGenerator > | cv::createFaceDetectionMaskGenerator () |
| anonymous enum |
#include <opencv2/objdetect.hpp>
| Ptr< BaseCascadeClassifier::MaskGenerator > cv::createFaceDetectionMaskGenerator | ( | ) |
#include <opencv2/objdetect.hpp>