目標
パラメータの理解
入力パラメータ
- samples : np.float32 データ型である必要があり、各特徴は単一の列に格納する。
- nclusters(K) : 最終的に必要なクラスタ数
- criteria : It is the iteration termination criteria. When this criteria is satisfied, algorithm iteration stops. Actually, it should be a tuple of 3 parameters. They are `( type, max_iter, epsilon )`:
- type of termination criteria. It has 3 flags as below:
- cv.TERM_CRITERIA_EPS - 指定した精度 epsilon に到達したらアルゴリズムの反復を停止する。
- cv.TERM_CRITERIA_MAX_ITER - 指定した反復回数 max_iter の後にアルゴリズムを停止する。
- cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER - 上記のいずれかの条件が満たされたら反復を停止する。
- max_iter - 最大反復回数を指定する整数。
- epsilon - 必要な精度
- attempts : 異なる初期ラベリングを用いてアルゴリズムを実行する回数を指定するフラグ。アルゴリズムは最良のコンパクトさを与えるラベルを返す。このコンパクトさは出力として返される。
- flags : このフラグは初期中心をどのように取るかを指定するために使う。通常はこのために2つのフラグが使われる: cv.KMEANS_PP_CENTERS と cv.KMEANS_RANDOM_CENTERS。
出力パラメータ
- compactness : 各点から対応する中心までの距離の二乗の総和である。
- labels : これはラベル配列(前の記事の 'code' と同じ)で、各要素は '0'、'1'... と印が付けられる。
- centers : これはクラスタ中心の配列である。
次に、3つの例を通して K-Means アルゴリズムの適用方法を見ていく。
1. 特徴が1つだけのデータ
特徴が1つだけ、つまり1次元のデータの集合があるとする。例として、Tシャツのサイズを決めるのに人の身長だけを使うTシャツ問題を取り上げる。
まずデータを作成し、Matplotlib でプロットすることから始める
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
ここでサイズ50の配列 'z' があり、値は 0 から 255 の範囲を取る。'z' を列ベクトルに reshape した。これは特徴が2つ以上ある場合により役立つ。その後、データを np.float32 型にした。
次の画像が得られる :
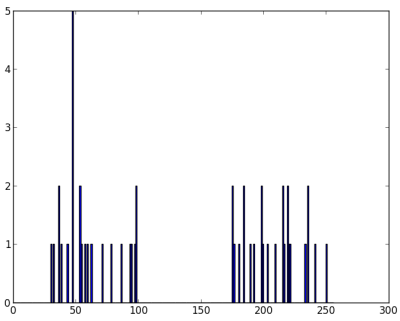
image
次に KMeans 関数を適用する。その前に基準を指定する必要がある。私の基準は、アルゴリズムの反復が10回実行されるか、精度 epsilon = 1.0 に達したら、アルゴリズムを停止して答えを返す、というものである。
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
flags = cv.KMEANS_RANDOM_CENTERS
compactness,labels,centers =
cv.kmeans(z,2,
None,criteria,10,flags)
double kmeans(InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers=noArray())
Finds centers of clusters and groups input samples around the clusters.
これにより compactness、labels、centers が得られる。この場合、centers として 60 と 207 が得られた。labels はテストデータと同じサイズになり、各データはその重心に応じて '0'、'1'、'2' などとラベル付けされる。次に、ラベルに応じてデータを異なるクラスタに分割する。
A = z[labels==0]
B = z[labels==1]
次に A を赤色、B を青色、それらの重心を黄色でプロットする。
plt.hist(A,256,[0,256],color = 'r')
plt.hist(B,256,[0,256],color = 'b')
plt.hist(centers,32,[0,256],color = 'y')
plt.show()
以下が得られた出力である:
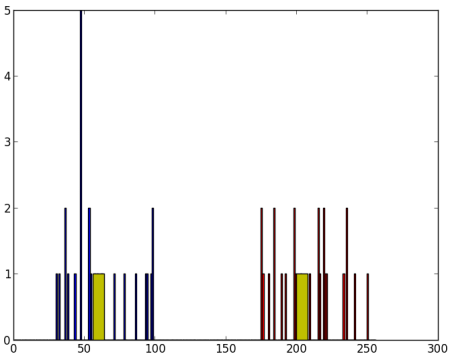
image
2. 複数の特徴を持つデータ
前の例では、Tシャツ問題に身長だけを用いた。ここでは身長と体重の両方、つまり2つの特徴を用いる。
前のケースでは、データを単一の列ベクトルにしたことを思い出してほしい。各特徴は列に並べられ、各行は1つの入力テストサンプルに対応する。
例えばこの場合、サイズ 50x2 のテストデータを設定する。これは50人の身長と体重である。最初の列は50人全員の身長に対応し、2番目の列は彼らの体重に対応する。最初の行は2つの要素を含み、1つ目は最初の人の身長、2つ目はその体重である。同様に、残りの行は他の人々の身長と体重に対応する。以下の画像を確認してほしい:
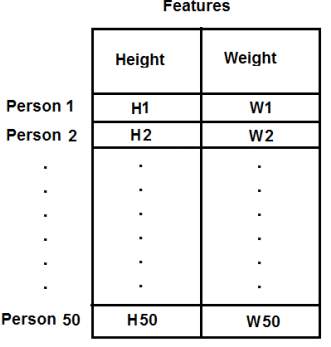
image
それでは直接コードに移る:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
X = np.random.randint(25,50,(25,2))
Y = np.random.randint(60,85,(25,2))
Z = np.vstack((X,Y))
Z = np.float32(Z)
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=
cv.kmeans(Z,2,
None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()
以下が得られる出力である:
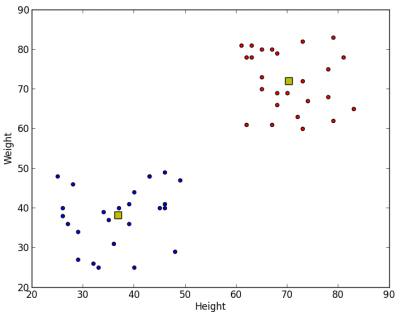
image
3. カラー量子化
色の量子化とは、画像中の色数を削減する処理である。これを行う理由の1つはメモリの削減である。デバイスによっては、限られた数の色しか生成できないという制限がある場合もある。そうした場合にも色の量子化が行われる。ここでは色の量子化に k-means クラスタリングを用いる。
ここで新たに説明することは何もない。特徴は R、G、B の3つである。したがって画像を Mx3 サイズの配列に reshape する必要がある(M は画像中のピクセル数)。そしてクラスタリングの後、重心の値(これも R、G、B である)をすべてのピクセルに適用すると、結果の画像は指定した数の色を持つことになる。そして再び、それを元の画像の形状に reshape し直す必要がある。以下がコードである:
import numpy as np
import cv2 as cv
Z = img.reshape((-1,3))
Z = np.float32(Z)
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=
cv.kmeans(Z,K,
None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
void imshow(const String &winname, InputArray mat)
Displays an image in the specified window.
int waitKey(int delay=0)
Waits for a pressed key.
void destroyAllWindows()
Destroys all of the HighGUI windows.
Mat imread(const String &filename, int flags=IMREAD_COLOR_BGR)
Loads an image from a file.
K=8 の結果を以下に示す:

image