|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
Haar特徴ベースのカスケード分類器を用いた物体検出は、Paul ViolaとMichael Jonesが2001年の論文「Rapid Object Detection using a Boosted Cascade of Simple Features」で提案した効果的な手法である。これは機械学習ベースのアプローチであり、多数のポジティブ画像とネガティブ画像からカスケード関数を学習する。学習した関数を用いて、他の画像内の物体を検出する。
ここでは顔検出を扱う。アルゴリズムはまず、分類器を学習するために多数のポジティブ画像(顔が写っている画像)とネガティブ画像(顔が写っていない画像)を必要とする。次に、それらから特徴を抽出する必要がある。このために、下の画像に示すHaar特徴を用いる。これは畳み込みカーネルのようなものである。各特徴は、白い矩形の下にあるピクセルの和を黒い矩形の下にあるピクセルの和から引くことで得られる単一の値である。
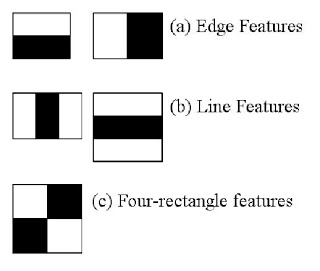
次に、各カーネルについて取り得るすべてのサイズと位置を使って、膨大な数の特徴を計算する。各特徴の計算では、白と黒の矩形の下にあるピクセルの和を求める必要がある。これを解決するため、彼らは積分画像 (integral images) を導入した。これにより、ピクセル数がどれほど多くても、ピクセルの和の計算をわずか4ピクセルだけを使う演算へと単純化できる。
しかし計算したこれらの特徴のうち、ほとんどは無関係である。例えば下の画像を考える。上段は2つの良い特徴を示している。最初に選択された特徴は、目の領域が鼻や頬の領域よりも暗いことが多いという性質に着目しているようだ。2番目に選択された特徴は、目が鼻梁よりも暗いという性質に依拠している。しかし同じウィンドウを頬やその他の場所に適用しても無関係である。では、160000を超える特徴の中から最良の特徴をどのように選ぶのか。これはAdaboostによって実現される。

このために、すべての学習画像にすべての特徴を一つずつ適用する。各特徴について、顔をポジティブとネガティブに分類する最良のしきい値を見つける。しかし当然、誤りや誤分類が生じる。誤り率が最小の特徴を選択するが、これは顔画像と非顔画像を最もよく分類する特徴を意味する。(この処理はこれほど単純ではない。最初は各画像に等しい重みが与えられる。各分類の後、誤分類された画像の重みが増やされる。そして再び同じ処理が行われる。新しい誤り率が計算される。新しい重みも同様である。この処理は、必要な精度または誤り率が達成されるか、必要な数の特徴が見つかるまで続けられる。)
最終的な分類器は、これらの弱分類器の重み付き和である。弱いと呼ばれるのは、単独では画像を分類できないが、他の分類器と組み合わせることで強い分類器を形成するためである。論文によれば、わずか200個の特徴でも95%の精度で検出できるという。最終的な構成では約6000個の特徴を持っていた。(160000を超える特徴から6000個の特徴への削減を想像してほしい。これは大きな利得である。)
では、ある画像を取る。それぞれの24x24ウィンドウを取る。それに6000個の特徴を適用する。顔かどうかをチェックする。なんと…なんと…少し非効率で時間がかかると思わないか。その通りである。著者らはこれに対して良い解決策を持っている。
画像において、画像領域のほとんどは非顔領域である。そのため、あるウィンドウが顔領域でないかどうかをチェックする簡単な方法を持つ方が良い考えである。もし顔領域でなければ、一度で破棄する。それを再び処理しない。代わりに顔があり得る領域に注力する。こうすることで、顔があり得る領域をチェックするための時間をより多く確保できる。
このために彼らは分類器のカスケード (Cascade of Classifiers)という概念を導入した。1つのウィンドウに6000個すべての特徴を適用する代わりに、特徴を分類器の異なる段 (stage) にグループ化し、一つずつ適用する。(通常、最初の数段に含まれる特徴の数はごくわずかである。)もしウィンドウが最初の段で不合格になれば、それを破棄する。残りの特徴は考慮しない。もし合格すれば、2番目の段の特徴を適用し、処理を続ける。すべての段を通過したウィンドウが顔領域である。この計画はどうだろう!!!
著者らの検出器は6000を超える特徴を持ち、38段から成り、最初の5段にはそれぞれ1, 10, 25, 25, 50個の特徴があった。(上の画像の2つの特徴は、実際にはAdaboostによって最良の2つの特徴として得られたものである。)著者らによれば、平均してサブウィンドウあたり6000を超える特徴のうち10個が評価される。
以上が、Viola-Jones顔検出がどのように動作するかについての簡単で直感的な説明である。詳細は論文を読んでほしい。
ここでは検出を扱う。OpenCVには、顔・目・笑顔などのための学習済み分類器が多数すでに含まれている。これらのXMLファイルはopencv_contrib/modules/xobjdetect/data/haarcascades/フォルダに格納されている。OpenCVで顔と目の検出器を作成してみよう。
次の関数を使う: detectMultiScale (image, objects, scaleFactor = 1.1, minNeighbors = 3, flags = 0, minSize = new cv.Size(0, 0), maxSize = new cv.Size(0, 0))
| image | 物体が検出される画像を含む CV_8U 型の行列。 |
| objects | 矩形のベクトルで、各矩形は検出された物体を1つ含む。矩形は元画像の外側に部分的にはみ出すことがある。 |
| scaleFactor | 各画像スケールで画像サイズをどれだけ縮小するかを指定する引数。 |
| minNeighbors | 各候補矩形を保持するために、それぞれが持つべき近傍の数を指定する引数。 |
| flags | 古いカスケードに対して、関数 cvHaarDetectObjects と同じ意味を持つ引数。新しいカスケードでは使われない。 |
| minSize | 可能な最小の物体サイズ。これより小さい物体は無視される。 |
| maxSize | 可能な最大の物体サイズ。これより大きい物体は無視される。maxSize == minSize の場合、モデルは単一スケールで評価される。 |
上記のコードを使ってこのデモを試してみよう。haarCascadeDetectionCanvasInput と haarCascadeDetectionCanvasOutput という名前のキャンバス要素が用意されている。画像を選び、Try it をクリックして結果を確認する。テキストボックス内のコードを変更して、さらに詳しく調べることができる。