|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
前のチュートリアル: G-APIによる顔解析パイプライン
次のチュートリアル: G-APIによる顔の美化アルゴリズムの実装
このチュートリアルでは以下を学ぶ:
このチュートリアルは 勾配構造テンソルによる異方性画像セグメンテーション に基づいている。
始める前に、元のアルゴリズムの実装を確認しておこう。
関数calcGST()は明らかに画像処理パイプラインである。
以上を考えると、calcGST()は出発点として最適な候補である。元のコードでは、そのプロトタイプは次のように定義されている。
G-APIでは、次のように定義できる。
重要なのは、新しいG-APIベースのバージョンのcalcGST()は、実際に値を計算する元のバージョンとは対照的に、計算グラフを生成するだけである点を理解することだ。これは原理的な違いであり、このようなG-APIベースの関数は実際のデータを処理するためではなく、グラフを構築するために使用される。
calcGST()の実装を、\(J\) 行列の計算から始めよう。元のコードは次のようになっている。
ここでは、すべての新しい演算に対して出力オブジェクトを宣言する必要がある(cv::Mat::convertTo の結果としてのimg、cv::Sobel および cv::multiply の結果としてのimgDiffXなどを参照)。
G-APIでの対応コードを以下に示す。
このスニペットは、G-APIと従来のOpenCVの間における次の構文上の違いを示している。
注意 – このコードは auto も使用している – img、imgDiffX などの中間オブジェクトの型は、C++コンパイラによって自動的に推論される。この例では、型はG-API演算の戻り値によって決まり、それらはすべて cv::GMat である。
G-APIの標準カーネルは可能な限りOpenCV APIの慣例に従おうとする – そのためcv::gapi::sobelは cv::Sobel と同じ引数を取り、cv::gapi::mul は cv::multiply に従う、といった具合である(戻り値を持つ点を除く)。
calcGST()関数の残りの部分も、同じやり方で簡単に実装できる。以下にその全ソースコードを示す。
calcGST()がG-API言語で定義されたら、それに基づいてグラフを構築し、最終的に実行できる – 入力画像を渡して結果を得る。実行する前に、元のコードがどのようになっていたか見ておこう。
calcGST()のようなG-APIベースの関数は、それが処理コードではなく構築コードであるため、入力データに直接適用することはできない。計算を実行するには、cv::GComputation クラスの特別なオブジェクトを作成する必要がある。このオブジェクトは、我々のG-APIコード(G-APIのデータと演算の合成)を、C++11の std::function<> に似た呼び出し可能なオブジェクトとしてラップする。
cv::GComputation クラスには、グラフを定義するために使用できる複数のコンストラクタがある。一般に、ユーザはグラフの境界 – GComputationが定義される入力オブジェクトと出力オブジェクト – を渡す必要がある。そうするとG-APIは出力から入力への呼び出しフローを解析し、指定された境界の間にある演算でグラフを再構築する。これは複雑に聞こえるかもしれないが、実際にはコードは次のようになる。
このコードは元のものから少しだけ変わっている点に注意。結果画像の形成もパイプラインの一部になっている(cv::gapi::addWeighted で行われる)。
このG-APIパイプラインの結果は、(同じ入力画像を与えれば)元のものとビット単位で完全に一致する。

以下は、G-APIへ移植した異方性画像セグメンテーションの初期バージョンの全リストである。
G-APIで動作するアルゴリズムの最初の動くバージョンを手に入れたので、それを使ってG-APIの仕組みを調べて学ぶことができる。この章では2つの側面、すなわちグラフ構造の理解とメモリのプロファイリングを扱う。
G-APIは"Graph API"の略だが、上の例でグラフについて何か言及があっただろうか? これは初期の設計目標の1つであった – G-APIは、導入と移植の作業をより簡単にするために、式を念頭に置いて設計された。人々は通常、普通のコードを書くときにノードやエッジという観点で考えることはまずない。そのため、G-APIはGraph APIでありながら、ユーザにそのような考え方を強制しない。
しかしながら、cv::GComputation オブジェクトが定義されると、グラフは依然として暗黙的に構築される。生成されたグラフがどのように見えるかを調べることは、それが正しく生成されているか、本当に我々のアルゴリズムを表現しているかを確認するうえで有用である。また、グラフに冗長性がないか確認するために、グラフの構造を学ぶことも有用である。
G-APIは、生成したグラフを .dot ファイルにダンプできる。これは人気のあるオープンなグラフ可視化ソフトウェアである Graphviz で可視化できる。
グラフを .dot ファイルにダンプするには、アプリケーションを実行する前に GRAPH_DUMP_PATH をファイル名に設定する。例えば次のようにする。
$ GRAPH_DUMP_PATH=segm.dot ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi
これで、このファイルを次のような dot コマンドで可視化できる。
$ dot segm.dot -Tpng -o segm.png
あるいは xdot でインタラクティブに表示する(これらのパッケージのインストール方法については、お使いのディストリビューション/OSのドキュメントを参照のこと)。
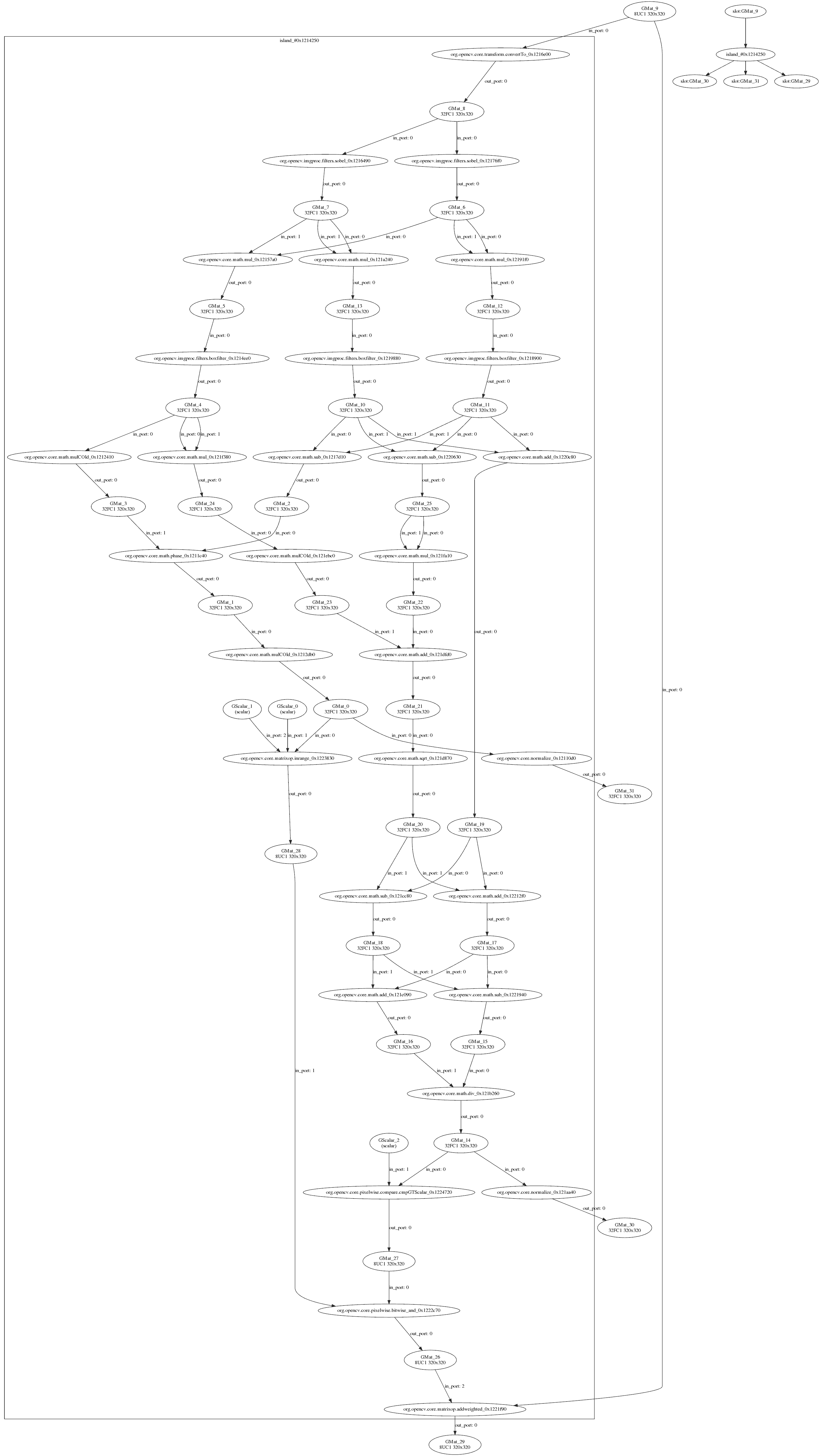
上の図は、G-APIの内部的なアルゴリズム表現に関する興味深い側面をいくつか示している。
アルゴリズムのメモリ使用量を、G-APIベースとOpenCVベースという2つのバージョンで計測し比較してみよう。現時点では、G-APIバージョンも内部でOpenCVの関数にフォールバックするため、OpenCVベースでもある。
GNU/Linuxでは、アプリケーションのメモリ使用量を Valgrind でプロファイルできる。Debian/Ubuntuシステムでは、次のようにインストールできる(管理者権限があると仮定)。
$ sudo apt-get install valgrind massif-visualizer
インストールが完了すれば、我々の2つのアルゴリズムバージョンについてメモリプロファイルを簡単に収集できる。
$ valgrind --tool=massif --massif-out-file=ocv.out ./bin/example_tutorial_anisotropic_image_segmentation ==6101== Massif, a heap profiler ==6101== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote ==6101== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==6101== Command: ./bin/example_tutorial_anisotropic_image_segmentation ==6101== ==6101== $ valgrind --tool=massif --massif-out-file=gapi.out ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi ==6117== Massif, a heap profiler ==6117== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote ==6117== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==6117== Command: ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi ==6117== ==6117==
完了したら、収集したプロファイルを Massif Visualizer(上記の手順でインストール済み)で確認できる。
以下は、このアルゴリズムのオリジナルのOpenCV版のメモリプロファイルを可視化したものである:
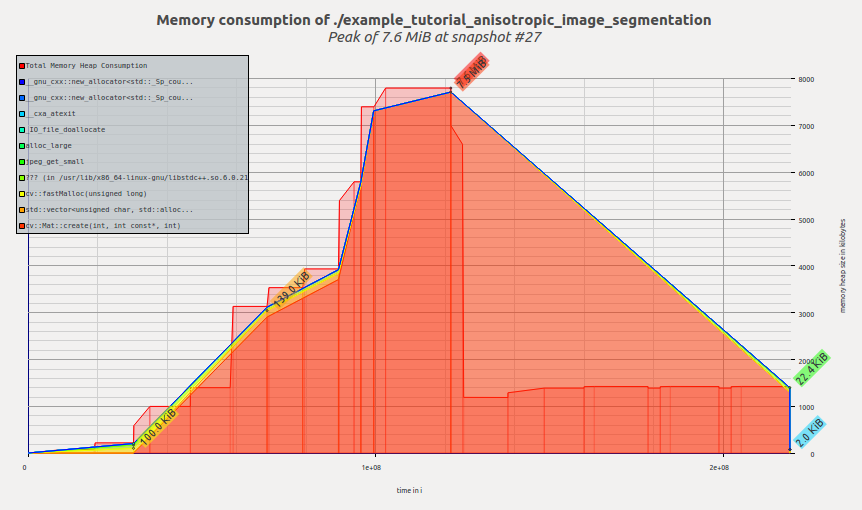
アプリケーションの実行に伴ってメモリが確保され、calcGST() 関数でピークに達することがわかる。その後、calcGST() の実行が完了し、すべての一時バッファが解放されると使用量が減少する。Massifはピーク時のメモリ消費量を7.6 MiBと報告している。
次に、G-API版のプロファイルを見てみよう:
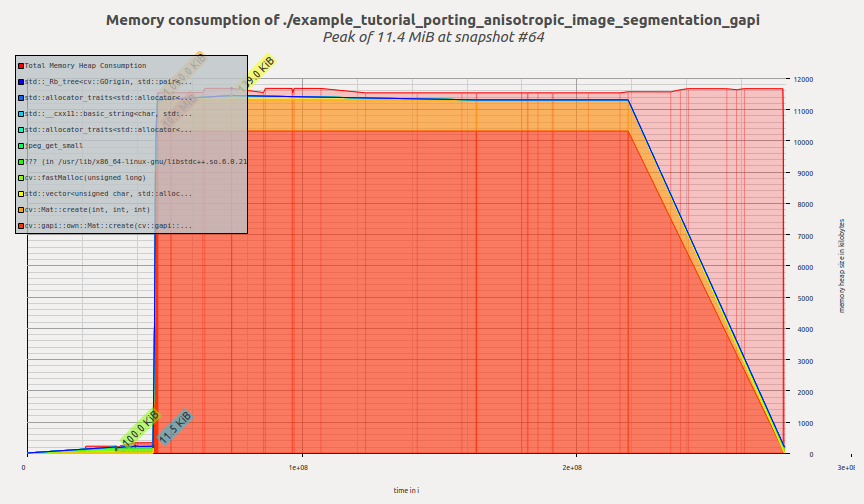
G-APIの計算が作成され実行が開始されると、G-APIは必要なメモリをすべて一度に確保し、その後はプログラムが終了するまでメモリプロファイルは平坦なまま保たれる。Massifはピーク時のメモリ消費量を11.4 MiBと報告している。
ここで読者は当然の疑問を持つかもしれない。G-APIはそれほど悪いのか? そもそも使う理由は何なのか?
幸いにも、そうではない。ここでメモリ消費量が増えているのは、このグラフの実行にデフォルトの素朴なOpenCVベースのバックエンドが使われているためである。このバックエンドは主に、オフロードやさらなる最適化を行う前にアルゴリズムを手早くプロトタイピングしデバッグするためのものである。
このバックエンドは、現時点ではそれが目的ではないため、複雑なメモリ管理戦略をまだ何も利用していない。次の章では、Fluidバックエンドについて学び、同じG-APIコードがまったく異なるモデルで実行され(使用量が数キロバイトにまで縮小する)様子を見ていく。
この章では、G-APIの計算を特別な方法で実行する方法、たとえば別のデバイスへオフロードしたり、特別な知能を用いてスケジューリングしたりする方法を扱う。G-APIはそのグラフをポータブルにするよう設計されている。つまり、いったんG-APIの用語でグラフを定義すれば、それをCPUで実行する場合でも、GPUで実行する場合でも、あるいは両方のデバイスで同時に実行する場合でも、グラフ自体には何の変更も必要としないということである。それを可能にする技術的詳細については、G-API High-level overview および G-API Kernel API がさらに詳しく解説している。この章では、G-API Fluidバックエンドを利用して、グラフをCPU上でキャッシュ効率の良いものにする。
G-APIは バックエンド (backend) を、カーネルの実行方法を知っている下位レベルのエンティティとして定義する。バックエンドは、そのバックエンド向けにカーネルをプログラムし統合するために使われる、異なる Kernel API を持つことがある(実際に持っている)。この文脈において カーネル (kernel) とは、最上位のAPIレベルで定義される 演算 (operation) の実装である(G_TYPED_KERNEL() マクロを参照)。
バックエンドはデバイスやプラットフォーム固有の事情を把握しているものであり、その固有の事情を念頭に置きながらカーネルを実行する。たとえば、G-APIの演算をHalide言語で記述(実装)し、G-APIグラフのうちうまく対応づけられる部分について機能するHalideコードを生成できる Halide バックエンドが考えられる。
OpenCV 4.0には2つのG-APIバックエンドが同梱されている。先ほど使ったデフォルトの「OpenCV」と、特別な「Fluid」バックエンドである。
Fluidバックエンドは、いわゆる「ストリーミング」モデルの実行を実装することで、メモリを節約しほぼ完璧なキャッシュ局所性を達成するように実行を再編成する。
Fluidカーネルの使用を始めるには、まず適切なヘッダファイル(デフォルトではインクルードされない)をインクルードする必要がある:
これらのヘッダをインクルードしたら、新しい カーネルパッケージ (kernel package) を構成してG-APIに指定できる:
G-APIでは、カーネル(すなわち演算の実装)はオブジェクトである。カーネルはコレクション、すなわち カーネルパッケージ (kernel package) にまとめられ、これはクラス cv::GKernelPackage で表される。カーネルパッケージの主な目的は、グラフで使いたいカーネルを取りまとめ、それを グラフのコンパイルオプション (graph compilation option) として渡すことである:
従来のOpenCVは論理的にモジュールへ分割されており、各モジュールが一連の関数を提供する。G-APIにも「モジュール」が存在し、それは特定のバックエンドが提供するカーネルパッケージとして表される。この例では、グラフ内で適切なFluid関数を利用するために、FluidカーネルパッケージをG-APIに渡す。
カーネルパッケージは結合可能である。上記の例では、「Core」と「ImgProc」のFluidカーネルパッケージを取り、それらを1つに結合している。cv::gapi::combine のドキュメントを参照のこと。
オプションでカーネルパッケージを何も指定しなければ、G-APIはデフォルトのOpenCV実装からなる デフォルト (default) パッケージを使用するため、G-APIグラフはデフォルトでOpenCV関数を介して実行される。OpenCVバックエンドは、他のどのバックエンドよりも広範な機能カバレッジを提供する。この例のようにカーネルパッケージが指定された場合は、それが デフォルト (default) と結合される。つまり、競合が起きた場合にはユーザ指定の実装がデフォルト実装を置き換えるということである。
上記の変更を行った後、(OpenCV 4.0では)アプリケーションは次のようなメッセージとともにクラッシュするはずである:
Fluidバックエンドには、OpenCV 4.0においていくつかの制限がある(より最新の状況についてはこの wikiページ を参照)。特に、このサンプルで使われているBoxフィルタは静的な3x3のカーネルサイズのみをサポートする。
この問題は、このサンプルでG-APIがBoxフィルタカーネルのFluid版を使わないようにすることで容易に回避できる。それは、先ほど作成したカーネルパッケージから該当するカーネルを取り除くことで実現できる:
これでこのカーネルパッケージは、(テンプレート引数として指定された)Boxフィルタカーネルインタフェースの実装を 一切 持たなくなった。上で述べたように、G-APIはこのカーネルを実行するためにOpenCVへフォールバックする。この変更を加えた結果のコードは次のようになる:
Fluidバックエンドに切り替えた後の、このサンプルのメモリプロファイルを調べてみよう。今度は次のようになる:
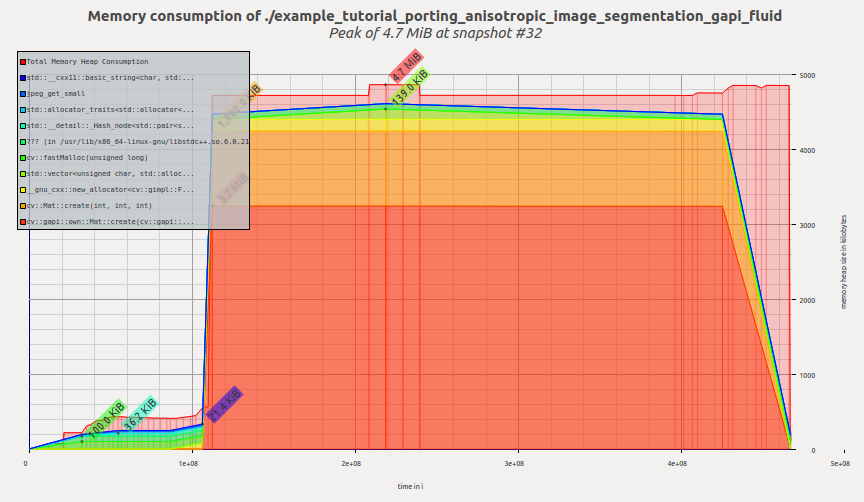
今度はツールが4.7MiBと報告している。しかもグラフ自体は変更せず、コードを数行変えただけである! これは以前のG-APIの結果に対して約2.4倍、オリジナルのOpenCV版に対して約1.6倍の改善である。
グラフの内部表現が今どうなっているかも調べてみよう。グラフを .dot にダンプすると、次のような可視化が得られる:
このグラフは(演算とデータオブジェクトという観点では)以前のバージョンと構造的に変わらないが、レイアウトが変わっている(ダンプの左側)ことが容易に見て取れる。
この可視化は、G-APIが混在グラフ、すなわち ヘテロジニアス (heterogeneous) グラフをどう扱うかを反映している。このグラフのほとんどの演算はFluidバックエンドで実装されているが、BoxフィルタはOpenCVバックエンドで実行される。グラフが(矩形によって)分割されていることが容易に見て取れる。G-APIは接続された演算をその親和性に基づいてグループ化し、サブグラフ (subgraph)(G-APIの用語では 島 (island))を形成する。こうして最上位のグラフは、複数のより小さなサブグラフの合成となる。各バックエンドはそのサブグラフ(島)をどう実行するかを決定するため、Fluidバックエンドは可能な限りメモリを最適化により省く一方、OpenCVのBoxフィルタがアクセスする6つの中間バッファは完全に確保され、最適化により省くことはできない。
このチュートリアルでは、G-APIとは何か、その主要な設計概念は何か、アルゴリズムをどのようにG-APIへ移植できるか、そしてその後にグラフモデルの利点をどう活用するかを示した。
OpenCV 4.0では、G-APIはまだ初期段階にある。今後のすべての作業の基盤という側面が強いが、現時点でも使用可能な状態である。
さらに、このチュートリアルは今後、カスタムカーネルのプログラミング、並列化などに関する新しい章で拡張される予定である。