|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
この章では、k近傍法 (kNN) アルゴリズムの概念を理解する。
kNNは、教師あり学習で利用できる最も単純な分類アルゴリズムの1つである。考え方は、特徴空間においてテストデータに最も近い一致を探索することである。以下の画像を用いてこれを見ていく。
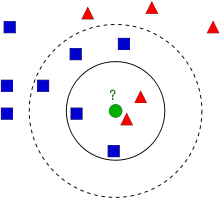
この画像には、青い四角形と赤い三角形という2つのファミリーがある。各ファミリーを クラス と呼ぶ。それらの家は、特徴空間 (Feature Space) と呼ぶ町の地図上に示されている。特徴空間は、すべてのデータが射影される空間と考えることができる。例えば、2D座標空間を考えてみよう。各データはx座標とy座標という2つの特徴を持つ。このデータを2D座標空間で表現できる。では、特徴が3つあると想像してほしい。3D空間が必要になる。次にN個の特徴を考えると、N次元空間が必要になる。このN次元空間がその特徴空間である。この画像では、2つの特徴を持つ2Dの場合として考えることができる。
次に、新しいメンバーが町にやってきて、緑の円で示される新しい家を作った場合に何が起こるかを考えてみよう。彼はこれらの青または赤のファミリー(あるいは クラス)のいずれかに加えられるべきである。このプロセスを 分類 (Classification) と呼ぶ。この新しいメンバーは正確にはどのように分類されるべきだろうか。ここではkNNを扱っているので、このアルゴリズムを適用してみよう。
単純な方法のひとつは、最も近い隣人が誰かを調べることである。画像から、それが赤い三角形ファミリーの一員であることは明らかだ。したがって、赤い三角形に分類される。この方法は、分類が最近傍 (nearest neighbour)のみに依存するため、単純に最近傍 (Nearest Neighbour)分類と呼ばれる。
しかし、このアプローチには問題がある。赤い三角形が最近傍かもしれないが、もし近くに青い四角形もたくさんあったらどうだろうか。その場合、その近傍では青い四角形のほうが赤い三角形よりも勢力が強いので、最も近いものだけを調べるのでは不十分である。代わりに、k個の最も近いファミリーを調べたいと考えるかもしれない。そして、その中で多数を占めるファミリーが何であれ、新参者はそのファミリーに属するべきである。この画像で、k=3、すなわち最も近い3つの近傍を考えてみよう。新しいメンバーは2つの赤い近傍と1つの青い近傍を持つ(等距離に2つの青があるが、k=3なのでそのうち1つだけを取る)ので、やはり赤いファミリーに加えられるべきである。しかし、k=7を取ったらどうだろうか。すると、5つの青い近傍と2つの赤い近傍を持ち、青いファミリーに加えられるべきとなる。結果は選んだkの値によって変わる。kが奇数でない場合、上記のk=4の場合に起こるように、同数になる可能性があることに注意してほしい。新しいメンバーは最も近い4つの近傍として2つの赤と2つの青を持つことになり、分類を行うには同数を解消する方法を選ぶ必要がある。繰り返すと、この方法は分類がk個の最近傍 (k nearest neighbours)に依存するため、k近傍法 (k-Nearest Neighbour)と呼ばれる。
さて、kNNでは確かにk個の近傍を考慮しているが、すべてに等しい重要度を与えている。これは正当だろうか。たとえば、k=4の同数のケースを取ってみよう。見てわかるように、2つの赤い近傍は実際には他の2つの青い近傍よりも新しいメンバーに近いので、赤いファミリーに加えられる資格がより高い。これを数学的にどう説明すればよいだろうか。各近傍に対して、新参者との距離に応じた重みを与える。新参者に近いものほど高い重みを得て、遠いものほど低い重みを得る。そして、各ファミリーの合計重みを別々に加算し、より高い合計重みを得たファミリーに新参者を分類する。これは修正kNN (modified kNN)または重み付きkNN (weighted kNN)と呼ばれる。
では、ここで見られる重要な点は何だろうか。
では、このアルゴリズムがOpenCVでどう動作するか見てみよう。
ここでは、上記と同じように2つのファミリー(クラス)を使った簡単な例を行う。そして次の章では、さらに優れた例を行う。
ここでは、赤いファミリーをClass-0(0で表記)、青いファミリーをClass-1(1で表記)とラベル付けする。25個の近傍、すなわち25個の訓練データを作成し、それぞれをClass-0またはClass-1の一部としてラベル付けする。これはNumPyの乱数生成器の助けを借りて行える。
そして、Matplotlibの助けを借りてプロットできる。赤い近傍は赤い三角形として、青い近傍は青い四角形として表示される。
最初の画像と似たものが得られる。乱数生成器を使っているので、コードを実行するたびに異なるデータが得られる。
次にkNNアルゴリズムを開始し、kNNを訓練するためにtrainDataとresponsesを渡す。(内部では探索木を構築する。詳しくは下記のAdditional Resourcesセクションを参照してほしい。)
そして、OpenCVのkNNの助けを借りて、1人の新参者を持ってきてあるファミリーに属するものとして分類する。kNNを実行する前に、テストデータ(新参者のデータ)について何か知っておく必要がある。データは \(number \; of \; testdata \times number \; of \; features\) のサイズを持つ浮動小数点配列であるべきである。そして、新参者の最近傍を見つける。k、すなわち欲しい近傍の数を指定できる。(ここでは3を使った。)これは以下を返す。
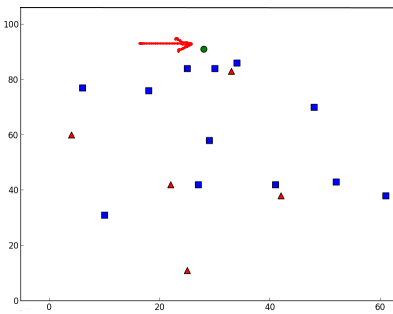
では、どう動作するか見てみよう。新参者は緑で示されている。
次の結果が得られた。
新参者の3つの最近傍はすべて青いファミリーからのものだと示している。したがって、青いファミリーの一部としてラベル付けされる。下のプロットから明らかである。
複数の新参者(テストデータ)がある場合は、単にそれらを配列として渡せばよい。対応する結果も配列として得られる。