|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
本章では、
背景差分は、多くのビジョンベースのアプリケーションにおける主要な前処理ステップである。例えば、固定カメラが部屋に出入りする来訪者の数をカウントする来訪者カウンターの場合や、車両に関する情報を抽出する交通カメラの場合などを考えてみる。これらすべての場合において、まず人物や車両だけを抽出する必要がある。技術的には、静止した背景から動いている前景を抽出する必要がある。
来訪者のいない部屋の画像や車両のいない道路の画像のように、背景だけの画像があれば、これは簡単な作業である。新しい画像から背景を差し引くだけで、前景の物体だけが得られる。しかし、ほとんどの場合、そのような画像を持っていないことが多いため、手元にある画像から背景を抽出する必要がある。車両の影がある場合、さらに複雑になる。影も動くため、単純な差分ではそれも前景としてマークしてしまう。これが事態を複雑にする。
この目的のためにいくつかのアルゴリズムが提案されてきた。以下では、bgsegmモジュールの2つのアルゴリズムを見ていく。
これはガウス混合ベースの背景/前景セグメンテーションアルゴリズムである。P. KaewTraKulPongとR. Bowdenによる2001年の論文「An Improved Adaptive Background Mixture Model for Realtime Tracking with Shadow Detection」で紹介された。各背景ピクセルをK個のガウス分布の混合(K = 3〜5)でモデル化する手法を用いる。混合の重みは、それらの色がシーン内に留まる時間の割合を表す。背景である可能性が高い色は、より長くより静的に留まるものである。
コーディングでは、関数cv.bgsegm.createBackgroundSubtractorMOG()を使って背景オブジェクトを作成する必要がある。これには履歴の長さ、ガウス混合の数、しきい値などのいくつかの省略可能なパラメータがある。すべてデフォルト値に設定されている。次に、ビデオループ内でbackgroundsubtractor.apply()メソッドを使って前景マスクを取得する。
以下に簡単な例を示す:
(すべての結果は比較のために最後に示す)。
このアルゴリズムは、統計的な背景画像推定とピクセルごとのベイズ的セグメンテーションを組み合わせる。Andrew B. Godbehere、Akihiro Matsukawa、Ken Goldbergによる2012年の論文「Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation」で紹介された。論文によると、このシステムは2011年3月31日から7月31日まで、カリフォルニア州サンフランシスコのContemporary Jewish Museumで「Are We There Yet?」という成功したインタラクティブなオーディオアートインスタレーションを稼働させた。
背景のモデリングに最初の数フレーム(デフォルトでは120フレーム)を使用する。ベイズ推定を用いて前景の可能性がある物体を識別する確率的前景セグメンテーションアルゴリズムを採用している。推定は適応的であり、変動する照明に対応するために、古い観測よりも新しい観測の方が重く重み付けされる。クロージングやオープニングのようないくつかのモルフォロジーフィルタリング処理が、不要なノイズを除去するために行われる。最初の数フレームでは黒いウィンドウが表示される。
ノイズを除去するために、結果にモルフォロジーのオープニングを適用するとよい。
元のフレーム
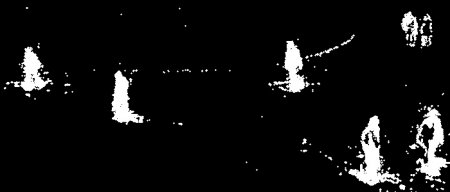
以下の画像はビデオの200番目のフレームを示している

BackgroundSubtractorMOGの結果
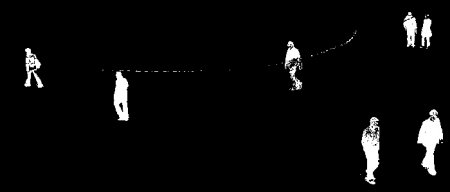
BackgroundSubtractorGMGの結果
モルフォロジーのオープニングでノイズが除去されている。