|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
本章では、
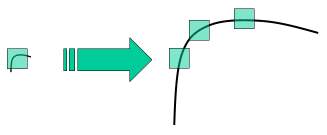
前の数章で、Harris などのコーナー検出器をいくつか見てきた。これらは回転不変であり、画像が回転しても同じコーナーを見つけられることを意味する。回転した画像でもコーナーはコーナーのままなので、これは当然である。しかしスケーリングについてはどうだろうか。画像がスケーリングされると、コーナーがコーナーでなくなることがある。例えば、下の簡単な画像を見てほしい。小さい画像の小さいウィンドウ内ではコーナーであっても、同じウィンドウで拡大すると平坦になる。よって Harris コーナーはスケール不変ではない。
2004年、ブリティッシュコロンビア大学の D.Lowe が、論文 Distinctive Image Features from Scale-Invariant Keypoints において、新しいアルゴリズムである Scale Invariant Feature Transform (SIFT) を提案した。これはキーポイントを抽出してその記述子を計算する。(この論文は理解しやすく、SIFT に関して入手可能な最良の資料とされている。本説明はこの論文の短い要約にすぎない)。
SIFT アルゴリズムには主に4つのステップがある。これらを一つずつ見ていく。
上の画像から明らかなように、異なるスケールのキーポイントを検出するために同じウィンドウを使うことはできない。小さいコーナーには問題ないが、より大きいコーナーを検出するにはより大きいウィンドウが必要である。このために、スケール空間フィルタリングが用いられる。そこでは、さまざまな \(\sigma\) 値で画像のガウシアンのラプラシアン(Laplacian of Gaussian, LoG)を求める。LoG はブロブ検出器として働き、 \(\sigma\) の変化によりさまざまなサイズのブロブを検出する。要するに、 \(\sigma\) はスケーリングパラメータとして機能する。例えば上の画像では、低い \(\sigma\) のガウシアンカーネルは小さいコーナーに対して高い値を与え、高い \(\sigma\) のガウシアンカーネルはより大きいコーナーによく適合する。よって、スケールと空間にわたる局所最大値を求めることができ、 \((x,y,\sigma)\) 値のリストが得られる。これは \(\sigma\) スケールにおいて (x,y) に潜在的なキーポイントがあることを意味する。
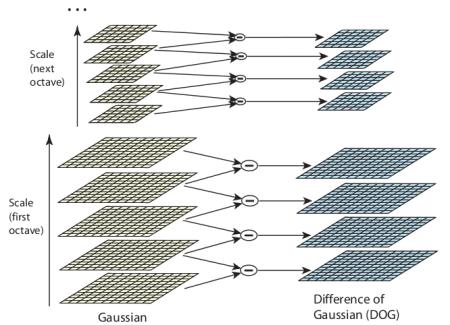
しかし、この LoG はやや計算コストが高いため、SIFT アルゴリズムは LoG の近似であるガウシアンの差分(Difference of Gaussians, DoG)を使う。ガウシアンの差分は、2つの異なる \(\sigma\)(それを \(\sigma\) と \(k\sigma\) とする)で画像をガウシアン平滑化した結果の差として得られる。この処理は、ガウシアンピラミッドにおける画像の異なるオクターブごとに行われる。これは下の画像に表されている。
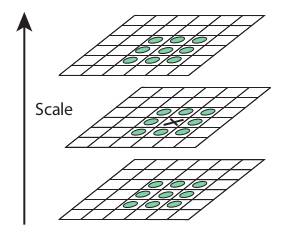
この DoG が求められると、画像はスケールと空間にわたって局所的な極値を探索される。例えば、画像中の1ピクセルは、その8近傍と、次のスケールの9ピクセル、および前のスケールの9ピクセルと比較される。局所的な極値であれば、それは潜在的なキーポイントである。基本的に、そのキーポイントがそのスケールで最もよく表現されることを意味する。これは下の画像に示されている。
さまざまなパラメータに関して、論文はいくつかの経験的データを示しており、最適値として次のようにまとめられる。オクターブ数 = 4、スケールレベル数 = 5、初期 \(\sigma=1.6\) 、 \(k=\sqrt{2}\) など。
潜在的なキーポイントの位置が見つかると、より正確な結果を得るためにそれらを精緻化する必要がある。彼らはスケール空間のテイラー級数展開を用いて極値のより正確な位置を求め、この極値での輝度がしきい値(論文によると0.03)未満であれば、それを棄却する。このしきい値は OpenCV では contrastThreshold と呼ばれる。
DoG はエッジに対して高い応答を示すため、エッジも除去する必要がある。このために、Harris コーナー検出器に似た概念が用いられる。彼らは主曲率を計算するために 2x2 のヘッセ行列(H)を用いた。Harris コーナー検出器から分かるように、エッジでは一方の固有値がもう一方より大きくなる。そこで彼らは次のような単純な関数を用いた。
この比がしきい値(OpenCV では edgeThreshold と呼ばれる)より大きい場合、そのキーポイントは破棄される。論文では10と与えられている。
これにより、低コントラストのキーポイントとエッジのキーポイントが除去され、残るのは強い関心点である。
次に、画像の回転に対する不変性を実現するため、各キーポイントに方向が割り当てられる。スケールに応じてキーポイント位置の周りの近傍を取り、その領域で勾配の大きさと方向を計算する。360度をカバーする36ビンの方向ヒストグラムを作成する(これは勾配の大きさと、キーポイントのスケールの1.5倍に等しい \(\sigma\) を持つガウシアン重み付きの円形ウィンドウによって重み付けされる)。ヒストグラムの最高ピークが取られ、その80%を超えるピークも方向の計算に考慮される。これにより、同じ位置とスケールだが異なる方向を持つキーポイントが生成される。これがマッチングの安定性に寄与する。
次にキーポイント記述子が作成される。キーポイントの周りに 16x16 の近傍を取る。これを 4x4 サイズの16個のサブブロックに分割する。各サブブロックについて、8ビンの方向ヒストグラムを作成する。よって合計128個のビン値が得られる。これがベクトルとして表現され、キーポイント記述子を形成する。これに加えて、照明変化や回転などに対する頑健性を実現するためのいくつかの対策が取られる。
2枚の画像間のキーポイントは、最近傍を特定することでマッチングされる。しかし場合によっては、2番目に近いマッチが1番目に非常に近いことがある。これはノイズやその他の理由で起こりうる。その場合、最近傍距離と2番目に近い距離との比を取る。この比が0.8より大きい場合、それらは棄却される。論文によると、これにより誤マッチの約90%が除去され、正しいマッチはわずか5%しか破棄されない。
以上が SIFT アルゴリズムの要約である。詳細と理解のために、原論文を読むことを強く推奨する。
では、OpenCV で利用できる SIFT の機能を見ていこう。これらは以前は opencv contrib リポジトリ でのみ利用可能だったが、2020年に特許が失効した。そのため、現在はメインリポジトリに含まれている。まずはキーポイントの検出と描画から始めよう。最初に SIFT オブジェクトを構築する必要がある。これにはさまざまなパラメータを渡すことができるが、それらは省略可能であり、ドキュメントで詳しく説明されている。
sift.detect() 関数は画像中のキーポイントを見つける。画像の一部のみを探索したい場合はマスクを渡せる。各キーポイントは特別な構造体であり、(x,y) 座標、意味のある近傍のサイズ、その方向を指定する角度、キーポイントの強度を指定する応答値など、多くの属性を持つ。
OpenCV はキーポイントの位置に小さな円を描く cv.drawKeyPoints() 関数も提供している。これにフラグ cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS を渡すと、キーポイントのサイズの円が描かれ、その方向まで表示される。下の例を参照。
以下の2つの結果を見てほしい。

次に記述子を計算するために、OpenCV は2つの方法を提供している。
ここでは2番目の方法を見ていく。
ここで kp はキーポイントのリストになり、des は形状 \(\text{(Number of Keypoints)} \times 128\) の numpy 配列になる。
これでキーポイントや記述子などが得られた。次は、異なる画像間でキーポイントをマッチングする方法を見ていきたい。それは次章で学ぶ。