|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
前のチュートリアル: OpenCVによるカメラキャリブレーション
次のチュートリアル: インタラクティブなカメラキャリブレーションアプリケーション
| 原著者 | Edgar Riba |
| 互換性 | OpenCV >= 5.0 |
今日では、拡張現実(AR)はコンピュータビジョンやロボティクス分野における最先端の研究テーマの一つである。拡張現実における最も基本的な問題は、コンピュータビジョン分野では後続の3Dレンダリングを行うために、ロボティクスでは把持や操作のために物体の姿勢を得るために、物体に対するカメラ姿勢を推定することである。しかし、これは簡単に解ける問題ではない。なぜなら、画像処理で最もよくある課題は、人間にとっては基本的で即座に解ける問題を解くために、多くのアルゴリズムや数学的演算を適用する際の計算コストだからである。
このチュートリアルでは、2D画像とそのテクスチャ付き3Dモデルが与えられたときに、6自由度を持つテクスチャ付き物体を追跡するためにカメラ姿勢を推定するリアルタイムアプリケーションの作り方を説明する。
このアプリケーションは以下の部分から構成される。
コンピュータビジョンにおいて、n個の3D-2D点対応からカメラ姿勢を推定することは、基本的でよく理解された問題である。最も一般的な形の問題では、姿勢の6自由度と5つのキャリブレーションパラメータ(焦点距離、主点、アスペクト比、スキュー)を推定する必要がある。これはよく知られたDirect Linear Transform (DLT)アルゴリズムを用いて、最小6個の対応で確立できる。ただし、DLTの精度を向上させる多様なアルゴリズムへとつながる、いくつかの簡略化が存在する。
最も一般的な簡略化は、キャリブレーションパラメータが既知であると仮定することであり、これはいわゆるPerspective-*n*-Point問題である。
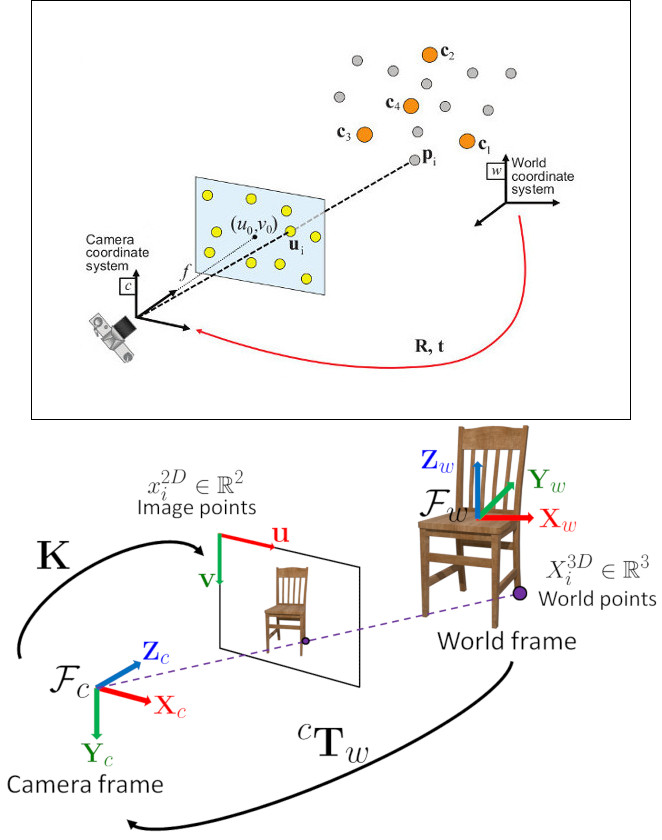
問題の定式化: ワールド基準座標系で表された3D点 \(p_i\) と、それらの画像上への2D投影 \(u_i\) の対応の組が与えられたとき、ワールドに対するカメラの姿勢( \(R\) と \(t\) )および焦点距離 \(f\) を求めることを目指す。
OpenCVはPerspective-*n*-Point問題を解くための4つの異なるアプローチを提供しており、それらは \(R\) と \(t\) を返す。その後、以下の式を用いて3D点を画像平面へ投影できる。
\[s\ \left [ \begin{matrix} u \\ v \\ 1 \end{matrix} \right ] = \left [ \begin{matrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{matrix} \right ] \left [ \begin{matrix} r_{11} & r_{12} & r_{13} & t_1 \\ r_{21} & r_{22} & r_{23} & t_2 \\ r_{31} & r_{32} & r_{33} & t_3 \end{matrix} \right ] \left [ \begin{matrix} X \\ Y \\ Z\\ 1 \end{matrix} \right ]\]
これらの方程式の扱い方に関する完全なドキュメントは 3d にある。
このチュートリアルのソースコードは、OpenCVソースライブラリの samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/ フォルダにある。
このチュートリアルは2つの主要なプログラムから構成される。
モデル登録
このアプリケーションは、検出対象の物体のテクスチャ付き3Dモデルを持っていないユーザー向けである。このプログラムを使って独自のテクスチャ付き3Dモデルを作成できる。このプログラムは平面物体に対してのみ動作するため、複雑な形状の物体をモデル化したい場合は、高度なソフトウェアを使って作成すべきである。
このアプリケーションは、登録する物体の入力画像とその3Dメッシュを必要とする。さらに、入力画像が撮影されたカメラの内部パラメータも与える必要がある。すべてのファイルは、絶対パス、またはアプリケーションの作業ディレクトリからの相対パスで指定する必要がある。ファイルが指定されない場合、プログラムは用意されたデフォルトパラメータを開こうとする。
このアプリケーションは、入力画像からORB特徴と記述子を抽出するところから始まり、次にメッシュと Möller–Trumbore交差判定アルゴリズム を用いて、見つかった特徴の3D座標を計算する。最後に、3D点と記述子はYAML形式のファイル内の異なるリストに格納され、各行が異なる点となる。ファイルの格納方法に関する技術的背景は、XML / YAML / JSONファイルを用いたファイル入出力 チュートリアルにある。

モデル検出
このアプリケーションの目的は、物体のテクスチャ付き3Dモデルが与えられたときに、その物体姿勢をリアルタイムで推定することである。
アプリケーションは、モデル登録プログラムで説明したのと同じ構造のYAMLファイル形式で3Dテクスチャ付きモデルを読み込んで起動する。シーンから、ORBの特徴量と記述子が検出・抽出される。次に、シーンの記述子とモデルの記述子間のマッチングを行うために cv::FlannBasedMatcher と cv::flann::GenericIndex が使われる。見つかったマッチと cv::solvePnPRansac 関数を用いて、カメラの R と t が計算される。最後に、不良なポーズを排除するためにKalmanFilterが適用される。
サンプル付きでOpenCVをコンパイルした場合は、opencv/build/bin/cpp-tutorial-pnp_detection にこれが見つかる。そして、アプリケーションを実行していくつかのパラメータを変更できる。
たとえば、pnpメソッドを変更してアプリケーションを実行できる。
ここでは、リアルタイムアプリケーションのコードを詳細に説明する。
テクスチャ付き3D物体モデルと物体メッシュを読み込む。
テクスチャ付きモデルを読み込むために、YAMLファイルを開いて格納された3D点とそれに対応する記述子を取得する関数 load() を持つ クラス Model を実装した。テクスチャ付き3Dモデルの例は samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/cookies_ORB.yml にある。
メインプログラムでは、モデルは次のように読み込まれる。
モデルメッシュを読み込むために、\(*\).ply ファイルを開いて物体の3D点および構成する三角形を格納する関数 load() を持つ クラス Mesh を実装した。モデルメッシュの例は samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.ply にある。
メインプログラムでは、メッシュは次のように読み込まれる。
別のモデルやメッシュを読み込むこともできる。
カメラまたはビデオから入力を取得する
検出するにはビデオをキャプチャする必要がある。これは、マシン上のビデオが置かれている絶対パスを渡して録画済みビデオを読み込むことで行う。アプリケーションをテストするには、samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.mp4 に録画済みビデオがある。
そしてアルゴリズムはフレームごとに計算される。
別の録画済みビデオを読み込むこともできる。
シーンからORB特徴と記述子を抽出する
次のステップは、シーンの特徴量を検出してその記述子を抽出することである。このタスクのために、キーポイント検出と特徴量抽出のための関数を持つ class RobustMatcher を実装した。これは samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/src/RobustMatcher.cpp にある。RobustMatch オブジェクトでは、OpenCVの任意の2D特徴量検出器を使用できる。今回は cv::ORB の特徴量を使用した。これはキーポイントの検出に cv::FAST を基にしており、記述子の抽出に cv::xfeatures2d::BriefDescriptorExtractor を使用するため、高速かつ回転に対してロバストである。ORB に関するより詳細な情報はドキュメントで確認できる。
以下のコードは、特徴検出器と記述子抽出器をインスタンス化して設定する方法である。
特徴と記述子は、マッチング関数の内部で RobustMatcher によって計算される。
Flannマッチャを使ってシーン記述子をモデル記述子とマッチングする
これは検出アルゴリズムの最初のステップである。主なアイデアは、現在のシーン内で見つかった特徴の3D座標を知るために、シーン記述子をモデル記述子とマッチングすることである。
まず、どのマッチャを使用するかを設定する必要がある。今回は cv::FlannBasedMatcher マッチャを使う。これは、学習済みの特徴コレクションが増えるにつれて、計算コストの面で cv::BFMatcher マッチャより高速である。そして、FlannBasedマッチャでは、ORB 記述子がバイナリであるため、作成されるインデックスは Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search となる。
LSH と探索パラメータを調整して、マッチングの効率を改善できる。
次に、robustMatch() または fastRobustMatch() 関数を使ってマッチャを呼び出す必要がある。この2つの関数を使う違いはその計算コストである。最初のメソッドは遅いが、2つの比率テストと対称性テストを使うため、良いマッチをフィルタリングする上でよりロバストである。対照的に、2番目のメソッドは高速だが、マッチに対して単一の比率テストしか適用しないためロバスト性は低い。
以下のコードは、モデルの3D点とその記述子を取得し、メインプログラムでマッチャを呼び出すものである。
以下のコードは、RobustMatcher クラスに属する robustMatch() 関数に対応する。この関数は、与えられた画像を使ってキーポイントを検出して記述子を抽出し、抽出した記述子と与えられたモデル記述子を 2近傍(two Nearest Neighbour) を使って双方向にマッチングする。そして、最良マッチと2番目に良いマッチの距離比が与えられたしきい値より大きいマッチを除去するために、両方向のマッチに比率テストを適用する。最後に、非対称なマッチを除去するために対称性テストを適用する。
マッチのフィルタリング後、得られた DMatches ベクトルを使って、見つかったシーンキーポイントと3Dモデルから2Dと3Dの対応を抽出する必要がある。cv::DMatch に関するより詳しい情報はドキュメントを参照のこと。
比率テストのしきい値や検出するキーポイント数を変更したり、ロバストマッチャを使うかどうかを変更したりすることもできる。
PnP + Ransacによる姿勢推定
2Dと3Dの対応が得られたら、カメラのポーズを推定するためにPnPアルゴリズムを適用する必要がある。cv::solvePnP ではなく cv::solvePnPRansac を使わなければならない理由は、マッチング後に見つかった対応がすべて正しいとは限らず、おそらく誤った対応、いわゆる 外れ値 (outliers) が存在するためである。Random Sample Consensus または Ransac は非決定論的な反復法であり、観測データから数学モデルのパラメータを推定し、反復回数が増えるにつれて近似的な結果を生成する。Ransac を適用した後、すべての 外れ値 が除去され、良好な解を一定の確率で得てカメラのポーズを推定する。
カメラ姿勢推定のために、クラス PnPProblem を実装した。この クラス は4つの属性を持つ。すなわち、与えられたキャリブレーション行列、回転行列、並進行列、回転並進行列である。姿勢推定に使用しているカメラの内部キャリブレーションパラメータが必要である。これらのパラメータを得るには、正方チェスボードによるカメラキャリブレーション と OpenCVによるカメラキャリブレーション のチュートリアルを確認できる。
以下のコードは、メインプログラムで PnPProblemクラス を宣言する方法である。
以下のコードは、PnPProblemクラス がその属性を初期化する方法である。
OpenCVは4つのPnPメソッド、ITERATIVE、EPNP、P3P、DLSを提供する。アプリケーションの種類に応じて推定メソッドは異なる。リアルタイムアプリケーションを作りたい場合は、最適解を見つける際にITERATIVEやDLSより高速であるため、EPNPとP3Pがより適している。しかし、EPNPとP3Pは平面に対して特にロバストというわけではなく、姿勢推定が鏡像効果を持つように見えることがある。したがって、このチュートリアルでは、検出対象の物体が平面を持つため、ITERATIVEメソッドが使われる。
OpenCVのRANSAC実装では、3つのパラメータを与える必要がある。1) アルゴリズムが停止するまでの最大反復回数、2) 観測された点投影と計算された点投影との間で、それをインライアとみなすために許容される最大距離、3) 良い結果を得るための信頼度である。アルゴリズムの性能を向上させるために、これらのパラメータを調整できる。反復回数を増やすとより正確な解が得られるが、解を見つけるのに時間がかかる。再投影誤差を増やすと計算時間は減るが、解は不正確になる。信頼度を下げるとアルゴリズムは高速になるが、得られる解は不正確になる。
以下のパラメータがこのアプリケーションで機能する。
以下のコードは、PnPProblemクラス に属する estimatePoseRANSAC() 関数に対応する。この関数は、2D/3D対応の組、使用する所望のPnPメソッド、出力インライアコンテナ、Ransacパラメータが与えられたときに、回転行列と並進行列を推定する。
次のコードには、メインアルゴリズムの3番目と4番目のステップがある。1つ目は上記の関数を呼び出すこと、2つ目はRANSACから出力されたインライアのベクトルを取り出して、描画用の2Dシーン点を取得することである。コードに見られるように、マッチがある場合にRANSACを適用するように注意しなければならない。そうでない場合、cv::solvePnPRansac 関数は無効な入力(点が不足している)に対してアサートを投げる。
最後に、カメラ姿勢が推定されたら、理論 で示した式を用いて、ワールド基準座標系で表された与えられた3D点の画像上への2D投影を計算するために \(R\) と \(t\) を使用できる。
以下のコードは、PnPProblemクラス に属する backproject3DPoint() 関数に対応する。この関数は、ワールド基準座標系で表された与えられた3D点を2D画像上へ逆投影する。
上記の関数は、物体の姿勢を表示するために物体 Mesh のすべての3D点を計算するのに使われる。
RANSACパラメータやPnPメソッドを変更することもできる。
不正な姿勢を棄却するための線形カルマンフィルタ
コンピュータビジョンやロボティクス分野では、検出や追跡の手法を適用した後、何らかのセンサ誤差により悪い結果が得られることはよくある。これらの不正な検出を避けるために、このチュートリアルでは線形カルマンフィルタの実装方法を説明する。カルマンフィルタは、与えられた数のインライアが検出された後に適用される。
カルマンフィルタ が何であるかについては、より詳しい情報を見つけることができる。このチュートリアルでは、ダイナミクスモデルと観測モデルを設定するために、位置と姿勢の追跡のための線形カルマンフィルタ に基づくOpenCV実装の cv::KalmanFilter を使用する。
まず、18個の状態を持つ状態ベクトルを定義する必要がある。位置データ (x,y,z) とその1次および2次導関数(速度と加速度)、次に3つのオイラー角(ロール、ピッチ、ヨー)の形で回転が追加され、それらの1次および2次導関数(角速度と角加速度)が加わる。
\[X = (x,y,z,\dot x,\dot y,\dot z,\ddot x,\ddot y,\ddot z,\psi,\theta,\phi,\dot \psi,\dot \theta,\dot \phi,\ddot \psi,\ddot \theta,\ddot \phi)^T\]
次に、観測数を定義する必要がある。これは6となる。すなわち \(R\) と \(t\) から \((x,y,z)\) と \((\psi,\theta,\phi)\) を取り出せる。さらに、システムに適用する制御入力の数を定義する必要があるが、この場合はゼロとなる。最後に、観測間の差分時間を定義する必要があり、この場合は \(1/T\) である。ここで T は動画のフレームレートである。
以下のコードはカルマンフィルタの初期化に対応する。まず、プロセスノイズ、観測ノイズ、誤差共分散行列を設定する。次に、動的モデルである遷移行列を設定し、最後に観測モデルである観測行列を設定する。
プロセスノイズと観測ノイズを調整してカルマンフィルタの性能を向上させることができる。観測ノイズを小さくするほど収束は速くなるが、その分アルゴリズムは不良な観測に対して敏感になる。
以下のコードはメインアルゴリズムの第5ステップである。Ransac後に得られたインライア数がしきい値を超えたとき、観測行列が埋められ、続いてカルマンフィルタが更新される:
以下のコードはfillMeasurements()関数に対応する。この関数は、観測された回転行列をオイラー角に変換し、観測された並進ベクトルとともに観測行列を埋める:
以下のコードはupdateKalmanFilter()関数に対応する。この関数はカルマンフィルタを更新し、推定された回転行列と並進ベクトルを設定する。推定された回転行列は、推定されたオイラー角から回転行列へ変換することで得られる。
第6ステップは、推定された回転・並進行列を設定することである:
最後の省略可能なステップは、求めた姿勢を描画することである。これを行うために、メッシュの3D点をすべて描画し、さらに参照座標軸を描画する関数を実装した:
カルマンフィルタを更新するための最小インライア数を変更することもできる:
以下の動画は、説明した検出アルゴリズムを用いて以下の引数でリアルタイム姿勢推定を行った結果である:
リアルタイムの姿勢推定はこちらのYouTubeで視聴できる。