|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
この章では、K-Meansクラスタリングの概念とその仕組みなどを理解する。
よく使われる例を用いてこれを扱う。
新しいモデルのTシャツを市場に投入しようとしている会社を考える。当然、あらゆる体型の人々を満足させるために、さまざまなサイズのモデルを製造しなければならない。そこで会社は人々の身長と体重のデータを取り、それを次のようにグラフ上にプロットする。
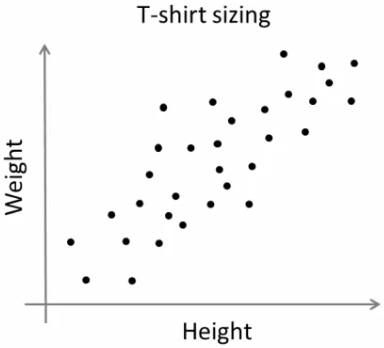
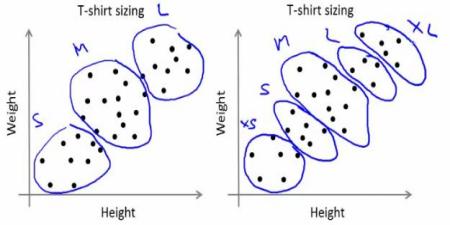
会社はすべてのサイズのTシャツを作ることはできない。代わりに、人々をSmall、Medium、Largeに分け、すべての人々に合うこれら3つのモデルだけを製造する。この人々を3つのグループに分けることは、k-meansクラスタリングによって行え、アルゴリズムはすべての人々を満足させる最良の3サイズを提供してくれる。そしてそれでも合わない場合、会社は人々をさらに多くのグループ、例えば5つなどに分けられる。下の画像を確認してほしい。
このアルゴリズムは反復処理である。画像の助けを借りて段階を追って説明する。
下のようなデータの集合を考える(Tシャツ問題として考えてもよい)。このデータを2つのグループにクラスタリングする必要がある。
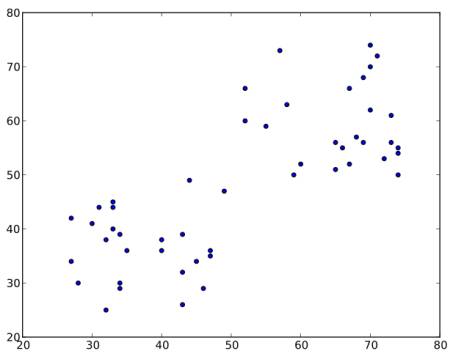
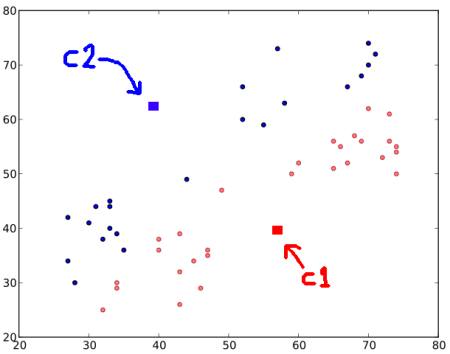
ステップ : 1 - アルゴリズムは2つのセントロイド \(C1\) と \(C2\) をランダムに選ぶ(任意の2つのデータをセントロイドとして取る場合もある)。
ステップ : 2 - 各点から両方のセントロイドまでの距離を計算する。あるテストデータが \(C1\) により近ければ、そのデータには'0'のラベルが付けられる。\(C2\) により近ければ'1'のラベルが付けられる(セントロイドがもっと多くあれば、'2'、'3'などとラベル付けされる)。
この例では、'0'のラベルが付いたものはすべて赤、'1'のラベルが付いたものは青で塗る。こうして、上記の操作の後に次の画像が得られる。
ステップ : 3 - 次に、すべての青い点と赤い点それぞれの平均を計算し、それが新しいセントロイドになる。つまり \(C1\) と \(C2\) が新しく計算されたセントロイドへ移動する。(なお、示されている画像は真の値ではなく、真の縮尺でもなく、あくまで説明のためだけのものである。)
そして再び、新しいセントロイドでステップ2を実行し、データに'0'と'1'のラベルを付ける。
こうして次の結果が得られる。
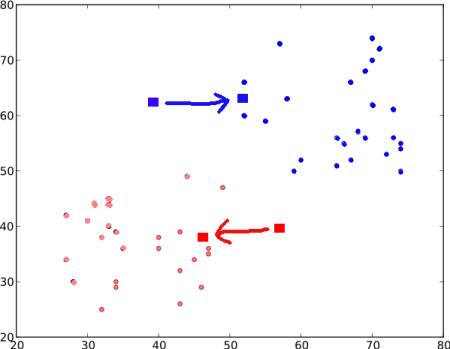
ここで ステップ - 2 と ステップ - 3 を、両方のセントロイドが固定点に収束するまで反復する。(または、最大反復回数や特定の精度に達したかなど、こちらが与える基準に応じて停止することもある。) これらの点は、テストデータとそれに対応するセントロイドとの間の距離の合計が最小になるような点である。 あるいは単純に言えば、\(C1 \leftrightarrow Red\_Points\) と \(C2 \leftrightarrow Blue\_Points\) の間の距離の合計が最小になる。
\[minimize \;\bigg[J = \sum_{All\: Red\_Points}distance(C1,Red\_Point) + \sum_{All\: Blue\_Points}distance(C2,Blue\_Point)\bigg]\]
最終結果はほぼ次のようになる。
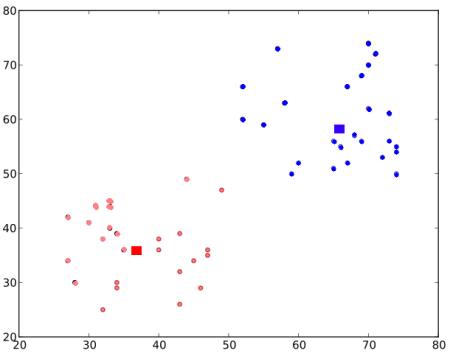
以上が、K-Meansクラスタリングの直感的な理解にすぎない。さらなる詳細と数学的な説明については、標準的な機械学習の教科書を読むか、追加リソースのリンクを確認してほしい。これはK-Meansクラスタリングのほんの表層にすぎない。このアルゴリズムには、初期セントロイドの選び方や反復処理の高速化の方法など、多くの改良がある。