|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
Hierarchical Data Format バージョン 5 のインターフェース。 さらに表示...
#include <opencv2/hdf/hdf5.hpp>
公開型 | |
| enum | { H5_UNLIMITED = -1 , H5_NONE = -1 , H5_GETDIMS = 100 , H5_GETMAXDIMS = 101 , H5_GETCHUNKDIMS = 102 } |
公開メンバ関数 | |
| virtual | ~HDF5 () |
| virtual void | atdelete (const String &atlabel)=0 |
| virtual bool | atexists (const String &atlabel) const =0 |
| virtual void | atread (double *value, const String &atlabel)=0 |
| virtual void | atread (int *value, const String &atlabel)=0 |
| virtual void | atread (OutputArray value, const String &atlabel)=0 |
| virtual void | atread (String *value, const String &atlabel)=0 |
| virtual void | atwrite (const double value, const String &atlabel)=0 |
| virtual void | atwrite (const int value, const String &atlabel)=0 |
| virtual void | atwrite (const String &value, const String &atlabel)=0 |
| virtual void | atwrite (InputArray value, const String &atlabel)=0 |
| virtual void | close ()=0 |
| hdf5 オブジェクトをクローズして解放する。 | |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel) const =0 |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel, const int compresslevel) const =0 |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel, const int compresslevel, const int *dims_chunks) const =0 |
| n 次元データセット(シングルチャンネルまたはマルチチャンネル型)のストレージを生成して確保する。 | |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel) const =0 |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel) const =0 |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel, const int *dims_chunks) const =0 |
| 2 次元シングルチャンネルまたはマルチチャンネルのデータセットのストレージを生成して確保する。 | |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel, const vector< int > &dims_chunks) const =0 |
| virtual void | dscreate (const vector< int > &sizes, const int type, const String &dslabel, const int compresslevel=HDF5::H5_NONE, const vector< int > &dims_chunks=vector< int >()) const =0 |
| virtual vector< int > | dsgetsize (const String &dslabel, int dims_flag=HDF5::H5_GETDIMS) const =0 |
| データセットのサイズを取得する。 | |
| virtual int | dsgettype (const String &dslabel) const =0 |
| データセットの型を取得する。 | |
| virtual void | dsinsert (InputArray Array, const String &dslabel) const =0 |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| Mat オブジェクトを指定されたデータセットに挿入または上書きし、unlimited プロパティが許せばデータセットサイズを自動的に拡張する。 | |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| hdf5ファイルから特定のデータセットを Mat オブジェクトに読み込む。 | |
| virtual void | dsread (OutputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| Mat オブジェクトをhdf5ファイルの指定されたデータセットに書き込むか上書きする。 | |
| virtual void | dswrite (InputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | grcreate (const String &grlabel)=0 |
| グループを作成する。 | |
| virtual bool | hlexists (const String &label) const =0 |
| ラベルが存在するかどうかを確認する。 | |
| virtual void | kpcreate (const int size, const String &kplabel, const int compresslevel=H5_NONE, const int chunks=H5_NONE) const =0 |
| cv::KeyPoint データセット用の専用ストレージを生成して確保する。 | |
| virtual int | kpgetsize (const String &kplabel, int dims_flag=HDF5::H5_GETDIMS) const =0 |
| キーポイントデータセットのサイズを取得する。 | |
| virtual void | kpinsert (const vector< KeyPoint > keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| 指定したデータセットに KeyPoint のリストを挿入または上書きし、unlimited プロパティが許す場合はデータセットサイズを自動拡張する。 | |
| virtual void | kpread (vector< KeyPoint > &keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| hdf5 ファイルから特定のキーポイントデータセットを vector<KeyPoint> オブジェクトへ読み込む。 | |
| virtual void | kpwrite (const vector< KeyPoint > keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| KeyPoint のリストを hdf5 ファイルの指定したデータセットへ書き込みまたは上書きする。 | |
Hierarchical Data Format バージョン 5 のインターフェース。
このモジュールは hdf5 が正しくインストールされている場合にのみコンパイルされることに注意。
| anonymous enum |
| 列挙値 | |
|---|---|
| H5_UNLIMITED | 次元サイズは無制限。
|
| H5_NONE | 圧縮なし。
|
| H5_GETDIMS | データセットの次元情報を取得する。
|
| H5_GETMAXDIMS | データセットの最大次元情報を取得する。
|
| H5_GETCHUNKDIMS | データセットのチャンクサイズを取得する。
|
|
inlinevirtual |
|
pure virtual |
ルートグループから属性を削除する。
| atlabel | 削除する属性。 |
|
pure virtual |
|
pure virtual |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
ルートグループから属性を読み込む。
| value | 属性の読み込み先となるアドレス |
| atlabel | 属性名 |
次の例は、cv::String 型の属性を読み込む方法を示す:
|
pure virtual |
ルートグループから属性を読み込む。
| value | 属性値。現時点では、n次元の連続したマルチチャンネル配列のみサポートされている。 |
| atlabel | 属性名。 |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
ルートグループ内に属性を書き込む。
| value | 属性値。 |
| atlabel | 属性名。 |
次の例は、cv::String 型の属性を書き込む方法を示す:
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
ルートグループに属性を書き込む。
| value | 属性値。現時点では、n次元の連続したマルチチャンネル配列のみサポートされている。 |
| atlabel | 属性名。 |
|
pure virtual |
hdf5 オブジェクトをクローズして解放する。
|
pure virtual |
|
pure virtual |
|
pure virtual |
n 次元データセット(シングルチャンネルまたはマルチチャンネル型)のストレージを生成して確保する。
| n_dims | 次元数を指定する |
| sizes | 各次元のサイズを格納した配列 |
| type | 使用する型。例えば CV_8UC3、CV_32FC1 など。 |
| dslabel | hdf5 データセットのラベルを指定する。既存のデータセットラベルを指定するとエラーになる。 |
| compresslevel | 使用する圧縮レベル 0〜9 を指定する。H5_NONE がデフォルト値で、圧縮なしを意味する。値 0 も圧縮なしを意味する。値 9 は最良の圧縮率を示す。圧縮レベルが高いほど計算コストも高くなる点に注意。圧縮には GNU gzip を利用する。 |
| dims_chunks | 配列の各メンバーは、ブロック I/O に使用するチャンクサイズを指定する。デフォルトの NULL はチャンクをまったく使用しないことを意味する。 |
|
pure virtual |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
2 次元シングルチャンネルまたはマルチチャンネルのデータセットのストレージを生成して確保する。
| rows | 行数を指定する |
| cols | 列数を指定する |
| type | 使用する型。例えば CV_8UC3、CV_32FC1 など。 |
| dslabel | hdf5 データセットのラベルを指定する。既存のデータセットラベルを指定するとエラーになる。 |
| compresslevel | 使用する圧縮レベル 0〜9 を指定する。H5_NONE がデフォルト値で、圧縮なしを意味する。値 0 も圧縮なしを意味する。値 9 は最良の圧縮率を示す。圧縮レベルが高いほど計算コストも高くなる点に注意。圧縮には GNU gzip を利用する。 |
| dims_chunks | 配列の各メンバーは、ブロック I/O に使用するチャンクサイズを指定する。デフォルトの NULL はチャンクをまったく使用しないことを意味する。 |
|
pure virtual |
これは利便性のために提供されているオーバーロードされたメンバ関数である。上記の関数とは、受け取る引数のみが異なる。
|
pure virtual |
|
pure virtual |
データセットのサイズを取得する。
| dslabel | 測定対象の hdf5 データセットのラベルを指定する。 |
| dims_flag | H5_GETDIMS ではデータセットの次元、H5_GETMAXDIMS ではデータセットの最大次元、H5_GETCHUNKDIMS ではチャンクサイズを取得する。 |
データセットの各次元のサイズを格納した vector オブジェクトを返す。
|
pure virtual |
データセットの型を取得する。
| dslabel | 確認対象の hdf5 データセットのラベルを指定する。 |
格納された行列の型を返す。これは CvMat の型システムと互換性のある識別子であり、例えば CV_16SC5(16 ビット符号付き 5 チャンネル配列)などである。
|
pure virtual |
|
pure virtual |
|
pure virtual |
Mat オブジェクトを指定されたデータセットに挿入または上書きし、unlimited プロパティが許せばデータセットサイズを自動的に拡張する。
| Array | 書き込む Mat データ配列を指定する。 |
| dslabel | 書き込み先となる hdf5 データセットのラベルを指定する。 |
| dims_offset | 配列の各メンバーは、InputArray をデータセットに(上書き)書き込む開始位置を、データセットの各次元についてのオフセットとして指定する。 |
| dims_counts | 配列の各メンバーは、InputArray からデータセットへ書き込むデータ量を、データセットの各次元について指定する。 |
Mat オブジェクトを対象のデータセットに書き込み、許可されていればデータセットの次元を自動拡張する。
|
pure virtual |
|
pure virtual |
|
pure virtual |
|
pure virtual |
hdf5ファイルから特定のデータセットを Mat オブジェクトに読み込む。
| Array | 読み込んだデータが返される Mat コンテナ。 |
| dslabel | 読み込み元となる hdf5 データセットのラベルを指定する。 |
| dims_offset | 配列の各メンバーは、データセットから OutputArray への読み込みを開始する位置を、各次元についてのオフセットとして指定する。 |
| dims_counts | 配列の各要素は、データセットの各次元のうち OutputArray に読み込むデータ量を指定する。 |
格納されたデータセットを反映する Mat オブジェクトを読み出す。
|
pure virtual |
|
pure virtual |
|
pure virtual |
|
pure virtual |
Mat オブジェクトをhdf5ファイルの指定されたデータセットに書き込むか上書きする。
| Array | 書き込む Mat データ配列を指定する。 |
| dslabel | 書き込み先となる hdf5 データセットのラベルを指定する。 |
| dims_offset | 配列の各メンバーは、InputArray をデータセットに(上書き)書き込む開始位置を、データセットの各次元についてのオフセットとして指定する。 |
| dims_counts | 配列の各要素は、InputArray からデータセットへ書き込むデータ量をデータセットの各次元について指定する。 |
Mat オブジェクトを対象のデータセットに書き込む。
|
pure virtual |
|
pure virtual |
グループを作成する。
| grlabel | hdf5 グループのラベルを指定する。 |
デフォルトのプロパティでhdf5グループを作成する。グループは作成後に自動的にクローズされる。
この例では、Group1 が SubGroup1 という1つのサブグループを持つ:
HDFViewツールを使って可視化した対応する結果は次のとおりである
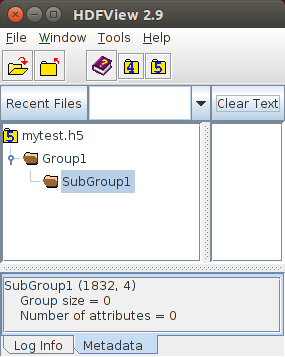
|
pure virtual |
ラベルが存在するかどうかを確認する。
| label | hdf5 データセットのラベルを指定する。 |
データセットが存在する場合はtrueを、そうでない場合はfalseを返す。
|
pure virtual |
cv::KeyPoint データセット用の専用ストレージを作成し割り当てる。
| size | KeyPoint の固定数を宣言する |
| kplabel | hdf5 データセットのラベルを指定する。同じラベルの既存データセットがあれば上書きされる。 |
| compresslevel | 使用する圧縮レベル 0-9 を指定する。H5_NONE がデフォルトで、圧縮なしを意味する。 |
| chunks | ブロック I/O に使用するチャンクサイズを各配列要素で指定する。H5_NONE がデフォルトで、圧縮なしを意味する。 |
|
pure virtual |
キーポイントデータセットのサイズを取得する。
| kplabel | 測定対象の hdf5 データセットのラベルを指定する。 |
| dims_flag | H5_GETDIMS ではデータセットの次元を取得し、H5_GETMAXDIMS ではデータセットの最大次元を取得する。 |
キーポイントデータセットのサイズを返す。
|
pure virtual |
KeyPoint のリストを指定したデータセットに挿入または上書きし、無制限プロパティが許す場合はデータセットのサイズを自動拡張する。
| keypoints | 書き込むキーポイントデータのリストを指定する。 |
| kplabel | 書き込み先となる hdf5 データセットのラベルを指定する。 |
| offset | データセット上でキーポイントを(上書き)書き込む先のオフセット位置を指定する。 |
| counts | データセットに書き込むキーポイントの数を指定する。 |
vector<KeyPoint> オブジェクトを対象のデータセットに書き込み、許可されている場合はデータセットの次元を自動拡張する。
|
pure virtual |
hdf5ファイルから特定のキーポイントデータセットを vector<KeyPoint> オブジェクトとして読み込む。
| keypoints | 読み込んだデータが返される vector<KeyPoint> コンテナ。 |
| kplabel | 読み込み元となる hdf5 データセットのラベルを指定する。 |
| offset | データセット上で読み込みを開始するオフセット位置を指定する。 |
| counts | データセットから読み込むキーポイントの数を指定する。 |
格納されたデータセットを反映した vector<KeyPoint> オブジェクトを読み出す。
|
pure virtual |
KeyPoint のリストをhdf5ファイルの指定したデータセットに書き込む、または上書きする。
| keypoints | 書き込むキーポイントデータのリストを指定する。 |
| kplabel | 書き込み先となる hdf5 データセットのラベルを指定する。 |
| offset | データセット上でキーポイントを(上書き)書き込む先のオフセット位置を指定する。 |
| counts | データセットに書き込むキーポイントの数を指定する。 |
vector<KeyPoint> オブジェクトを対象のデータセットに書き込む。