|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
前のチュートリアル: サポートベクターマシン入門
| 原著者 | Fernando Iglesias García |
| 互換性 | OpenCV >= 3.0 |
このチュートリアルでは、以下の方法を学ぶ:
線形分離できない訓練データを扱うためにSVMの最適化問題を拡張することには、なぜ意義があるのか。コンピュータビジョンでSVMが用いられる用途の多くは、単純な線形分類器よりも強力なツールを必要とする。これは、こうしたタスクでは 訓練データを超平面で分離できることはまれである という事実に起因する。
こうしたタスクの一つ、たとえば顔検出を考えてみる。この場合の訓練データは、顔である画像の集合と、顔でない画像の集合(顔以外のあらゆるもの)から構成される。この訓練データは非常に複雑であり、顔の集合全体を顔でない集合全体から線形に分離できるような各サンプルの表現(特徴ベクトル)を見つけることは困難である。
SVMによって分離超平面が得られることを思い出してほしい。したがって、訓練データが線形分離できない以上、見つかった超平面はサンプルの一部を誤分類することを認めざるを得ない。この 誤分類 は、考慮すべき最適化の新たな変数となる。新しいモデルには、最大のマージンを与える超平面を見つけるという従来の要件と、分類誤りを過度に許容せずに訓練データを正しく汎化するという新たな要件の両方を含める必要がある。
ここでは、マージン を最大化する超平面を求める最適化問題の定式化から出発する(これは前のチュートリアル(サポートベクターマシン入門)で説明されている)。
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i\]
このモデルを修正して誤分類誤差を考慮に入れる方法は複数ある。たとえば、同じ量に、訓練データ中の誤分類誤差の数に定数を掛けたものを加えて最小化することが考えられる。すなわち:
\[\min ||\beta||^{2} + C \text{(misclassification errors)}\]
しかし、これはあまり良い解ではない。いくつかの理由があるが、その一つとして、本来属すべき決定領域からわずかな距離で誤分類されたサンプルと、そうでないサンプルを区別していないことが挙げられる。したがって、より良い解は 誤分類されたサンプルから正しい決定領域までの距離 を考慮する。すなわち:
\[\min ||\beta||^{2} + C \text{(distance of misclassified samples to their correct regions)}\]
訓練データの各サンプルに対して、新たな引数 \(\xi_{i}\) を定義する。これらの引数はそれぞれ、対応する訓練サンプルから正しい決定領域までの距離を保持する。次の図は、2つのクラスからなる線形分離できない訓練データ、分離超平面、および誤分類されたサンプルから正しい領域までの距離を示している。
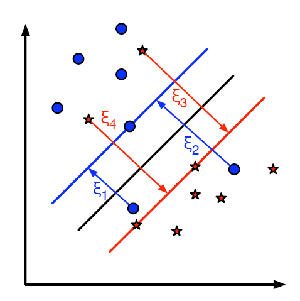
図に現れる赤線と青線は、各決定領域に対するマージンである。各 \(\xi_{i}\) が、誤分類された訓練サンプルから、本来属すべき領域のマージンまでを表していることを理解することが非常に 重要 である。
最終的に、最適化問題の新しい定式化は次のようになる:
\[\min_{\beta, \beta_{0}} L(\beta) = ||\beta||^{2} + C \sum_{i} {\xi_{i}} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 - \xi_{i} \text{ and } \xi_{i} \geq 0 \text{ } \forall i\]
引数 C はどのように選べばよいのか。この問いの答えが訓練データの分布の仕方に依存することは明らかである。一般的な答えはないが、次の規則を考慮に入れると役立つ:
ソースコードはOpenCVソースライブラリの ml/samples フォルダにもある。あるいは ここからダウンロード できる。
この演習の訓練データは、2つの異なるクラスのいずれかに属する、ラベル付き2D点の集合で構成される。演習をより興味深いものにするため、訓練データは一様確率密度関数 (PDF) を用いてランダムに生成される。
訓練データの生成は2つの主要な部分に分けている。
最初の部分では、両クラスについて線形分離可能なデータを生成する。
2番目の部分では、両クラスについて線形分離できない、重なり合うデータを生成する。
ここで行う設定と、参照元とする前のチュートリアル(サポートベクターマシン入門)で行った設定との違いは、わずか2点だけである。
C。ここでは、最適化において誤分類誤差を過度に罰しないよう、この引数に小さな値を選んだ。これは、直感的に期待される解に近いものを得たいという考えに基づいている。ただし、この引数を調整して問題への理解を深めることを推奨する。
SVMモデルを構築するために cv::ml::SVM::train メソッドを呼び出す。訓練処理にはかなり長い時間がかかる場合があることに注意する。プログラムを実行する際は気長に待ってほしい。
cv::ml::SVM::predict メソッドは、訓練済みSVMを用いて入力サンプルを分類するために使われる。この例では、SVMが行った予測に応じて空間に色を付けるためにこのメソッドを使用した。言い換えると、画像を走査し、その各ピクセルをデカルト平面上の点として解釈する。各点は、SVMが予測したクラスに応じて色付けされ、ラベル1のクラスであれば濃い緑、ラベル2のクラスであれば濃い青で表示される。
cv::circle メソッドは、訓練データを構成するサンプルを表示するために使われる。ラベル1のクラスのサンプルは薄い緑で、ラベル2のクラスのサンプルは薄い青で表示される。
ここでは、サポートベクトルに関する情報を得るためにいくつかのメソッドを使用する。cv::ml::SVM::getSupportVectors メソッドはすべてのサポートベクトルを取得する。ここでは、このメソッドを使ってサポートベクトルである訓練サンプルを見つけ、それらを強調表示している。

この実行例は こちらのYouTube で確認できる。