|
OpenCV 5.0.0
Open Source Computer Vision
|
読み込み中...
検索中...
見つかりません
|
OpenCV 5.0.0
Open Source Computer Vision
|
次のチュートリアル: 線形分離不可能なデータに対するサポートベクターマシン
| 原著者 | Fernando Iglesias García |
| 互換性 | OpenCV >= 3.0 |
このチュートリアルでは、以下の方法を学ぶ:
サポートベクターマシン (SVM) は、分離超平面によって形式的に定義される識別的な分類器である。言い換えると、ラベル付き学習データ (教師あり学習) が与えられると、アルゴリズムは新しい事例を分類する最適な超平面を出力する。
得られる超平面はどのような意味で最適なのか? 次の単純な問題を考えてみよう。
2つのクラスのいずれかに属する線形分離可能な2次元点の集合に対して、それらを分離する直線を求める。
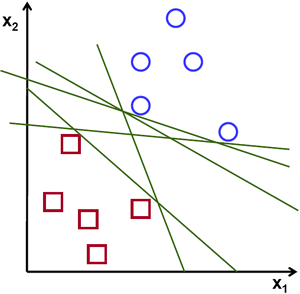
上の図を見ると、この問題の解となる直線が複数存在することがわかる。そのうちのどれかが他より優れているだろうか? 直線の良し悪しを見積もる基準を直感的に定義できる。 ある直線が点に近すぎる位置を通る場合、その直線はノイズに敏感で正しく汎化できないため、悪い直線である。 したがって、我々の目標は、すべての点からできるだけ遠くを通る直線を見つけることであるべきだ。
そこで、SVMアルゴリズムの動作は、学習事例までの最小距離が最大となる超平面を見つけることに基づいている。この距離の2倍は、SVMの理論においてマージンという重要な名前で呼ばれる。したがって、最適な分離超平面は学習データのマージンを最大化する。
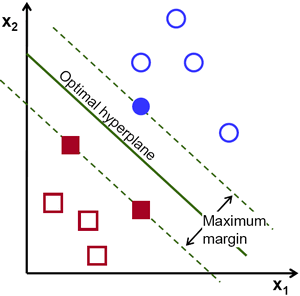
超平面を形式的に定義するために用いる記法を導入しよう。
\[f(x) = \beta_{0} + \beta^{T} x,\]
ここで \(\beta\) は重みベクトル、\(\beta_{0}\) はバイアスとして知られる。
最適な超平面は、\(\beta\) と \(\beta_{0}\) のスケーリングによって無限に多くの異なる方法で表現できる。慣例として、超平面のあらゆる表現の中から選ばれるのは次のものである。
\[|\beta_{0} + \beta^{T} x| = 1\]
ここで \(x\) は超平面に最も近い学習事例を表す。一般に、超平面に最も近い学習事例はサポートベクターと呼ばれる。この表現は正準超平面として知られる。
ここで、点 \(x\) と超平面 \((\beta, \beta_{0})\) の間の距離を与える幾何学の結果を用いる。
\[\mathrm{distance} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||}.\]
特に、正準超平面の場合、分子は1に等しく、サポートベクターまでの距離は次のようになる。
\[\mathrm{distance}_{\text{ support vectors}} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||} = \frac{1}{||\beta||}.\]
前節で導入したマージンは、ここでは \(M\) と表記し、最も近い事例までの距離の2倍であることを思い出そう。
\[M = \frac{2}{||\beta||}\]
最後に、\(M\) を最大化する問題は、いくつかの制約条件のもとで関数 \(L(\beta)\) を最小化する問題と等価である。制約条件は、超平面がすべての学習事例 \(x_{i}\) を正しく分類するという要件をモデル化する。形式的には次のようになる。
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i,\]
ここで \(y_{i}\) は各学習事例のラベルを表す。
これはラグランジュ最適化の問題であり、ラグランジュ乗数を用いて解くことで、最適な超平面の重みベクトル \(\beta\) とバイアス \(\beta_{0}\) を得ることができる。
この演習の学習データは、2つの異なるクラスのいずれかに属する、ラベル付き2次元点の集合で構成されている。一方のクラスは1点から成り、もう一方は3点から成る。
この後で用いる関数 cv::ml::SVM::train は、学習データが浮動小数点数の cv::Mat オブジェクトとして格納されていることを要求する。そこで、上で定義した配列からこれらのオブジェクトを作成する。
SVMの引数を設定する
このチュートリアルでは、学習事例が線形分離可能な2つのクラスに分かれているという最も単純なケースで、SVMの理論を紹介した。しかし、SVMはさまざまな問題に利用できる (例えば、線形分離不可能なデータの問題や、カーネル関数を用いて事例の次元を引き上げるSVMなど)。その結果、SVMを学習させる前にいくつかの引数を定義しなければならない。これらの引数は cv::ml::SVM クラスのオブジェクトに格納される。
各引数の説明:
SVMによって分類された領域
メソッド cv::ml::SVM::predict は、学習済みSVMを用いて入力サンプルを分類するために使用する。この例では、SVMが行った予測に応じて空間を色分けするためにこのメソッドを使った。言い換えると、画像を走査し、そのピクセルをデカルト平面上の点として解釈する。各点は、SVMが予測したクラスに応じて色付けされる。ラベル1のクラスなら緑、ラベル-1のクラスなら青である。
サポートベクトル
ここでは、サポートベクターに関する情報を得るためにいくつかのメソッドを使用する。メソッド cv::ml::SVM::getSupportVectors はすべてのサポートベクターを取得する。ここではこのメソッドを使って、サポートベクターとなっている学習事例を見つけ、それらを強調表示している。
